
Last week was one of the most important AI weeks this year for software developers. Microsoft rolled out their all-new Visual Studio Code and GitHub Copilot Pro with massive amounts of new features focused on autonomous AI-based agent coding. They even launched it with a short movie of Satya Nadella “vibe coding” a computer simulator in less than 10 minutes without writing a single line of code. The March 2025 updates of Visual Studio Code and GitHub Copilot are two of the most important updates to Visual Studio Code ever, and not only did they add an autonomous agent mode for coding, they also added extras like full MCP Server support, Fetch mode, Thinking tool, support for custom API keys and custom models, and so much more. However, with all these new features comes great responsibility. I am myself not a fan of vibe coding and I always get the best results when I clearly steer the AI in a specific direction. So if you are an organization that has rolled out GitHub Copilot in your organization, be prepared to do some heavy work in the coming weeks when it comes to moderating how your developers should use these tools in the best way. I am quite sure you do not want your developers to switch to 100% AI generated vibe based source code.
OpenAI grew to 500 million unique weekly users, with Sam Altman saying the recent 4o update led to over one million sign-ups in an hour. In December 2024 OpenAI announced their goal to reach 1 billion unique users in 2025, and at this rate they will reach that point long before Christmas. This means that over 20% of the world’s entire population with Internet access will use ChatGPT on at least a weekly basis. If you add other services like Copilot, Claude, Gemini, and Llama, my prediction is that the figure will be closer to or above 50% of the world’s population using AI almost on a daily basis near the end of 2025. And it will spread from there. People will get used to not having to do boring, repetitive work, which means that if your company has not yet adopted AI agents for routine work, you better start now, because as soon as everyone begins to understand exactly what LLMs are capable of, they will do everything in their power to avoid doing boring routine work.
Among other news last week: Runway launched their amazing Gen-4 video generator, which now supports “world consistency” that lets users maintain a character’s exact appearance across multiple environments using just a single reference image. If you have time, check out the example movies I posted below, it’s crazy good. Also, for the first time, humans describe AI models as more human than actual humans in a Turing test. I have always said that by the end of 2025 you will no longer be able to detect if an AI wrote a piece of text or not. And it’s at that point many people will stop writing their own texts completely. How do you think that will affect us as a society going forward?
Thank you for being a Tech Insights subscriber!
THIS WEEK’S NEWS:
- Meta’s Llama 4 Underwhelms in Real-World Tests
- Visual Studio Code Launches Agent Mode with MCP Support for All Users
- Microsoft Blocks VSCode Extensions in Forks Like Cursor
- Amazon Launches Nova Act AI Model for Web Browser Automation
- AI Bots Consuming 65% of Wikipedia’s Critical Resources as Multimedia Traffic Surges
- Runway Gen-4: Consistency Breakthrough in AI Video Generation
- AI Therapy Chatbot Matches Human Therapists in Clinical Trial
- Chinese Firm EHang Receives First Permit for Pilotless Flying Taxis in China
- OpenAI PaperBench: Evaluating AI’s Ability to Replicate AI Research
- CodeScientist: AI2 Introduces Autonomous Research System
- Anthropic Launches Claude for Education with Learning Mode for Universities
- GPT-4.5 Passes Turing Test, Convincing Humans It’s Human 73% of the Time
- Google DeepMind Outlines Responsible AGI Development Framework
- Midjourney V7 Launches After Long Wait, Still Struggles with Hands
Meta’s Llama 4 Underwhelms in Real-World Tests
The News:
- Yesterday Meta released Llama 4, its latest suite of AI models featuring two variants: Llama 4 Scout and Llama 4 Maverick, with a third model called Llama 4 Behemoth in development.
- The models utilize a mixture-of-experts (MoE) architecture, with Llama 4 Maverick containing 17B active parameters and 400B total parameters, while Scout has 17B active parameters, 16 experts, and 109B total parameters.
- Llama 4 Scout dramatically increases context length from 128K in Llama 3 to 10 million tokens, enabling multi-document summarization and “reasoning over vast codebases” (according to Meta).
- Meta claims Llama 4 Maverick outperforms comparable models like GPT-4o and Gemini 2.0 on coding, reasoning, multilingual, long-context, and image benchmarks.
- The models are available for download via Meta or Hugging Face and power Meta AI across platforms including WhatsApp, Messenger, and Instagram Direct.
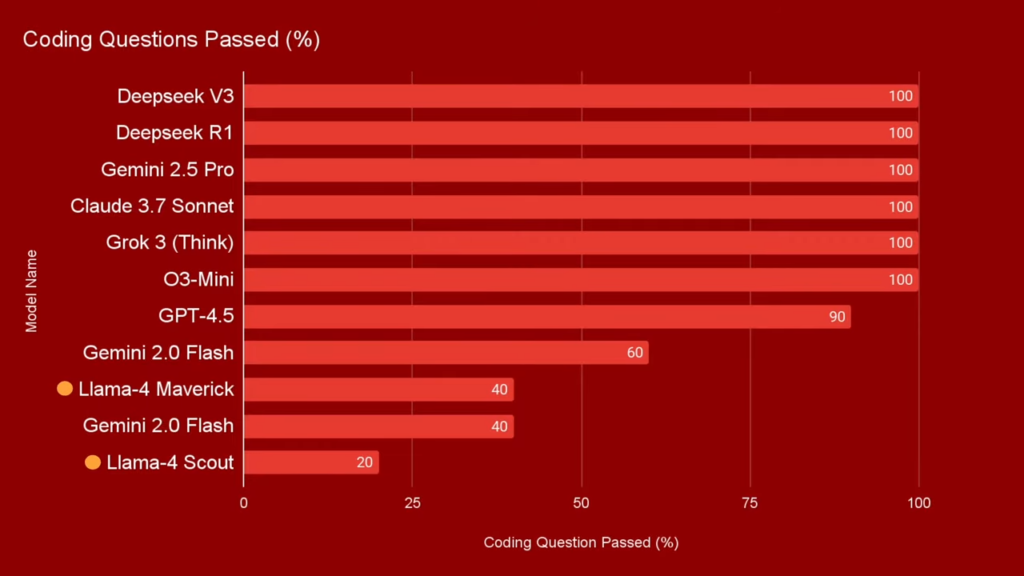
What you might have missed (1): Meta says these models outperforms GPT-4o, but actual tests show something completely different. Here are just a couple of comments from a Reddit thread posted yesterday: I’m incredibly disappointed with Llama-4 : r/LocalLLaMA. You might also want to check out the video LLAMA-4 (Fully Tested) – They have LOST THEIR ESSENCE & IT’S BAD
- “Llama-4-Maverick, the 402B parameter model, performs roughly on par with Qwen-QwQ-32B in terms of coding ability. Meanwhile, Llama-4-Scout is comparable to something like Grok-2 or Ernie 4.5.”
- “In my testing it performed worse than Gemma 3 27B in every way, including multimodal. Genuinely astonished how bad it is.”
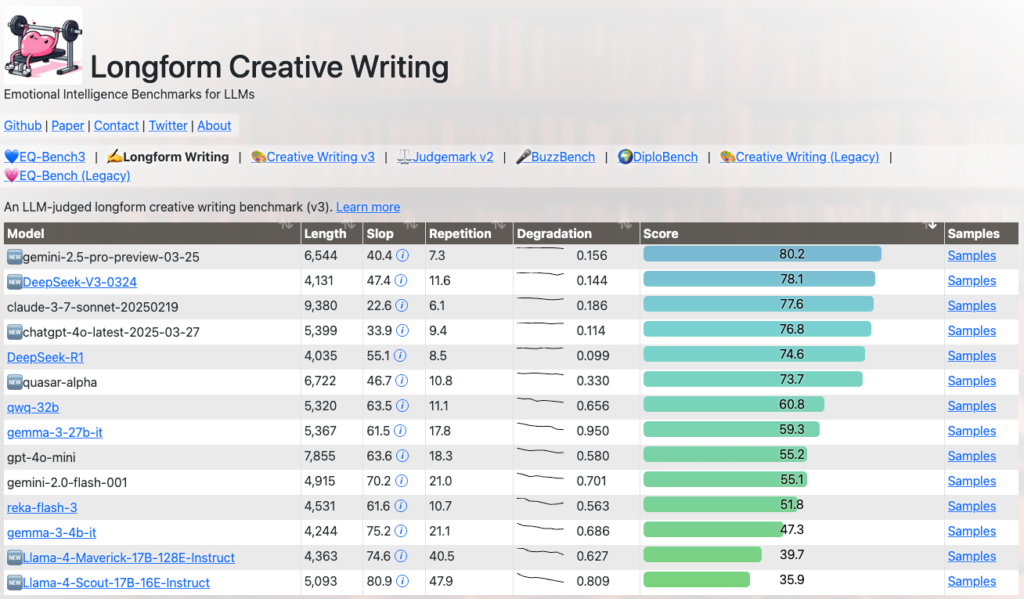
What you might have missed (2): Check out the “Longform Creative Writing” benchmark, and Llama 4 Scout and Maverick perform worst of all models in the graph, lower than Gemma 3 and QWQ-32B.
My take: Well this release was a surprise in many ways. First by Meta releasing the models on a Sunday, and then claiming that their models beat most closed-source models on coding and reasoning. And then reading up on all users testing the models and reporting that they perform worse than many of the smaller models, including Qwen QWQ-32B and Google Gemma 3-27B. And this with models that cannot even run on a H100 GPU without having to quantize it down to 4 bits with even worse performance as a result. Something seems off in so many ways with this release, and I’m not really sure what happened here. Maybe they published the wrong models online, and somehow released half-baked early internal releases? I guess we will learn more in the coming week.
Read more:
- The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation
- I’m incredibly disappointed with Llama-4 : r/LocalLLaMA
- EQ-Bench Longform Creative Writing Leaderboard
- LLAMA-4 (Fully Tested) + Free APIs + Cline & RooCode: They have LOST THEIR ESSENCE & IT’S BAD. – YouTube
Visual Studio Code Launches Agent Mode with MCP Support for All Users

The News:
- Microsoft released the March 2025 (version 1.99) update for Visual Studio Code, making GitHub Copilot’s Agent Mode generally available to all users after being in preview.
- Agent Mode provides an autonomous editing experience where Copilot plans and executes tasks based on natural language requests, determines relevant files, applies code changes, and suggests terminal commands while keeping users in control to review and confirm actions.
- The update also includes Model Context Protocol (MCP) server support, allowing AI models to interact with external tools and data sources, plus built-in tools for fetching web content, finding symbol references, and deep analysis.
- Parallel to this, GitHub introduced a new premium request system with rate limits for advanced AI models, while keeping unlimited access to the base model (GPT-4o) for all paid plans.
- A new Copilot Pro+ tier has been launched at $39/month, offering 1,500 monthly premium requests and access to the best models like GPT-4.5, compared to 300 premium requests for the $10/month Pro tier.
What you might have missed: Here’s a fun video of Satya Nadella vibe coding an Altair emulator using the new agent mode in Visual Studio Code. Rolling out agentic mode to every Visual Studio Code user will be like showing every person how ChatGPT works for the first time, this will have an incredible impact on all software development!
My take: 😳 Just wow, what an amazing release of Visual Studio Code! If you are a developer and are working in Visual Studio Code or Cursor, you should go straight to the release notes. I tried it over the weekend with my projects and it worked really well. It now uses premium requests when using it with Claude 3.7, so it’s almost as fast as Cursor including code merging. Microsoft also added a “thinking tool” which I wrote about last week, which significantly increases performance on complex tasks by letting the agent think between tool calls. And they added a “fetch tool” that automatically includes content from a publicly accessible webpage in your prompt. And they added support for Bring Your Own Key (BYOK), that allows you to bring your own API keys for providers such as Azure, Anthropic, Gemini, Open AI, Ollama, and Open Router. This allows you to use new models that are not natively supported by Copilot the very first day that they’re released.
I’m seriously quite stunned by this release. It’s so good it makes me want to code lots of stuff just for fun. For all you companies that have rolled out GitHub Copilot across your entire organization – congratulations, this is the release you have been waiting for! Just be aware that 300 premium requests which is the standard in Copilot Pro or Copilot Business it not much and will probably be used up within a week or less. Be prepared to go for the Enterprise (1000/month) or Pro+ (1500/month) subscriptions once your developers get up to speed with AI development and really start using MCP and agentic tools on scale in their daily work.
Read more:
Microsoft Blocks VSCode Extensions in Forks Like Cursor
https://github.com/getcursor/cursor/issues/2976

The News:
- Microsoft has begun enforcing restrictions that prevent VSCode-derived editors, such as Cursor, from using Microsoft’s official extensions, impacting developers who rely on these tools for their workflow.
- The C/C++ extension has been confirmed as blocked, with users receiving a message stating the extension “may be used only with Microsoft Visual Studio, Visual Studio Code, Azure DevOps, Team Foundation Server, and successor Microsoft products”.
- The timing coincides with Microsoft’s release of their own Agent mode for VSCode (as noted above), suggesting a strategic move to protect their ecosystem as they expand their AI-assisted coding capabilities.
- Alternative solutions exist for some blocked extensions, with users recommending clangd as a superior replacement for the Microsoft C++ extension, noting it “gives way better error messages and has faster indexing”.
- The restriction is based on the VS Code Marketplace Terms of Use, which has always specified that Marketplace Offerings are intended exclusively for Visual Studio Products and Services.
My take: Microsoft official C/C++ extension has over 80 million installations, compared to clangd which has almost 2 million. This will go two ways – either will all Cursor & C/C++ users switch to clangd, or they will switch back to Visual Studio Code. Microsoft is clearly betting on the latter. Cursor as a company just hit $200 in ARR, just a few months after reaching $100M. Every developer I know of that has tried working with Cursor loves it, and want to make it their main environment. But now you have the same setup in Visual Studio Code with GitHub Copilot Pro+, not only Agent and MCP support but also thinking tool, fetch tool and support for custom API keys. It’s everything users loved from Cursor but in a tool that’s approved by most IT departments. This release of Visual Studio code changes everything, and there’s a good chance Cursor will drop like a rock in terms of revenue in the coming months, especially with their recent issues with context windows as I reported on last week.
Amazon Launches Nova Act AI Model for Web Browser Automation
https://labs.amazon.science/blog/nova-act
The News:
- Amazon has released Nova Act, a new AI model trained to perform actions within web browsers, enabling developers to build agents that can automate tasks like submitting out-of-office requests, setting calendar holds, and configuring away-from-office emails.
- Nova Act SDK allows developers to break down complex workflows into reliable atomic commands (search, checkout, answering questions about the screen) and add detailed instructions where needed, while also enabling API calls and direct browser manipulation through Playwright.
- The model achieves over 90% accuracy on internal evaluations of challenging UI interactions like date picking, drop-downs, and popups, outperforming competitors with 93.9% accuracy on ScreenSpot Web Text interactions compared to Claude 3.7 Sonnet (90.0%) and OpenAI CUA (88.3%).
- Nova Act is currently available as a research preview to developers through nova.amazon.com, where users can experiment with an early version of the model.
- The technology is already being used in Alexa+ to navigate the internet in a self-directed way when integrated services can’t provide all necessary APIs.
My take: AI models are getting increasingly good at browsing the web, and it’s important to note that until just recently this was not something we specifically trained them on. The more we train them to do this, the better they will get, and Nova Act is a good example of this. This will have significant impact on many businesses that hide content behind costly APIs but allow users to access the same information freely from the web. With AI Agents being able to browse exactly like a human, the line between API access and browser based access becomes quite thin. Every company will technically be able to retrieve any information they want in an automated way using browser based control. We’re not quite there yet, it’s still “only” at 90% accuracy, but within a year I think we will have AI models that can browse the web just as efficiently as the best human.
AI Bots Consuming 65% of Wikipedia’s Critical Resources as Multimedia Traffic Surges
https://diff.wikimedia.org/2025/04/01/how-crawlers-impact-the-operations-of-the-wikimedia-projects
The News:
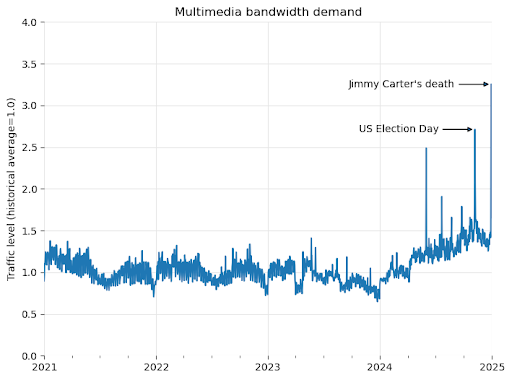
- Wikipedia’s bandwidth for multimedia content has jumped 50% since January 2024, primarily from AI companies scraping images to train their models.
- When Jimmy Carter died in December 2024, the combination of 2.8 million human page views and ongoing bot traffic created network congestion that slowed access for users.
- Bots account for only 35% of total pageviews but generate 65% of Wikipedia’s most resource-intensive traffic by accessing less popular pages that bypass caching systems.
- Wikipedia’s technical team found that many crawlers ignore robots.txt directives completely, with some commercial entities scraping content without respecting access limitations.
- The foundation now employs rate limiting and IP blocking for aggressive crawlers, balancing the need for content discovery against infrastructure protection.
My take: This is quite an interesting view on information and information access – and as Wikimedia states: “Our content is free, our infrastructure is not”. Now Wikimedia has to pay for AI bots to crawl and collect their data. With AI agents becoming smarter every month now, it’s getting increasingly difficult to block them since they can also configure massive IP subnets for operation and balance out the requests in a way that’s very difficult to track and block. I have said many times that I am convinced that the web will change as a result of AI agents, and now it’s clear that not only the appearance but also the infrastructure needs to change. It’s no longer enough to cache the most popular pages, you need to apply a caching mechanism that’s also AI agent optimized.
Read more:
Runway Gen-4: Consistency Breakthrough in AI Video Generation
https://runwayml.com/gen-4-bts

The News:
- Runway released Gen-4, their newest AI video model that solves the persistent problem of keeping characters and objects visually consistent across different scenes.
- The model introduces “world consistency” technology that lets users maintain a character’s exact appearance across multiple environments using just a single reference image.
- Technical improvements include more realistic physics simulation, with objects properly interacting with surfaces and environments instead of floating unnaturally.
- Gen-4 processes more complex text instructions, giving users finer control over camera movements, subject actions, and scene composition than previous versions.
- While initially limited to 720p resolution and shorter clips, Runway has added 4K upscaling, video transformation capabilities, and multi-angle scene generation without requiring custom training.
My take: 😳 Do you want to get seriously amazed with what AI Video Generation can do today? I mean so impressed you will call your best friend and tell them that “Video generation has changed forever this week!” Then go to this page “Behind the Scenes with Gen-4” and watch the beautiful videos there, they are all 100% made with Runway Gen-4.
I’m so impressed I don’t really know what to say, other than we just reached another tipping point. If you have been reading my newsletters you know I like talking about points in time when AI technologies becomes good enough in specific domains, then everyone starts using them. We reached that point last year with text generation, we reached it this year with programming (just look at the new release of Visual Studio Code), and we just got there with video generation. Is it perfect? No, there are still issues with dynamics etc. But it’s good enough for most use cases. And for people who know how to use these tools their performance will multiply, very similar to expert writers and developers that know how to use generative AI efficiently in their daily work.
Read more:
- Behind the Scenes with Gen-4
- Introducing Runway Gen-4 | Runway – YouTube
- Runways Text To Video “GEN 4” Actually Changes The Industry! – YouTube
- Runway releases an impressive new video-generating AI model | TechCrunch
AI Therapy Chatbot Matches Human Therapists in Clinical Trial
https://home.dartmouth.edu/news/2025/03/first-therapy-chatbot-trial-yields-mental-health-benefits

The News:
- Dartmouth researchers have completed the first clinical trial of “Therabot”, an AI therapy chatbot that produced significant mental health improvements comparable to traditional therapy.
- The trial involved 106 participants diagnosed with depression, anxiety, or eating disorders who experienced remarkable symptom reductions: 51% for depression, 31% for anxiety, and 19% for eating disorder concerns.
- Participants formed a “therapeutic alliance” with Therabot similar to what patients typically develop with human therapists, frequently initiating conversations and engaging with the app for an average of six hours (equivalent to eight therapy sessions).
- The AI chatbot uses evidence-based cognitive behavioral therapy techniques and includes safety protocols for high-risk situations, with researchers maintaining clinical oversight throughout the trial.
- Therabot offers 24/7 accessibility and personalized support, potentially helping address the significant gap in mental health care where there’s only one provider available for every 1,600 patients with depression or anxiety in the U.S.
My take: These results are comparable to gold-standard cognitive therapy, suggesting AI could meaningfully supplement traditional care models. Nicholas Jacobson, the study’s senior author, writes: “We’re talking about potentially giving people the equivalent of the best treatment you can get in the care system over shorter periods of time”. If you or anyone you know has suffered from depression or anxiety you know how difficult it can be to get the proper care. While Therabot isn’t meant to replace human therapists, it clearly shows how AI right now can help bridge critical gaps in our mental health infrastructure, especially for those who seek help during off-hours or who lack access to traditional care options. And who knows what it will be able to do within 2-3 years?
Chinese Firm EHang Receives First Permit for Pilotless Flying Taxis in China
https://www.ehang.com/news/1196.html

The News:
- EHang and partner Hefei Heyi Aviation last week obtained China’s first permit for autonomous passenger aircraft operations. The certification allows EHang to offer paid tourism and sightseeing flights in Guangzhou and Hefei.
- EHang’s EH216-S is a two-seat electric aircraft that can fly at 130 km/h for up to 35 kilometers, and initial flights will follow pre-set routes, returning to the takeoff point.
- EHang plans to expand to six more locations, including Shenzhen, pending approval.
My take: EHang’s vice president He Tianxing predicts that “flying taxis will become a viable method of transportation in China in the next three to five years”. If you asked me about this a few years ago I would have been a strong skeptic, but now EHang got a real permit to go live with fully autonomous flying taxis and this is actually happening. If you work in a medium sized city today you know it will take you at least an hour to travel 15-20 kilometers in rush hour, probably more. With an autonomous flying taxi drone it would take you less than 10 minutes.
Read more:
OpenAI PaperBench: Evaluating AI’s Ability to Replicate AI Research
https://openai.com/index/paperbench
The News:
- OpenAI introduced PaperBench, a benchmark that evaluates how well AI agents can replicate state-of-the-art AI research papers from scratch, including understanding contributions, developing code, and executing experiments.
- The benchmark requires agents to replicate 20 Spotlight and Oral papers from ICML 2024, with performance measured across 8,316 individually gradable tasks developed in collaboration with the original paper authors.
- Testing showed the best-performing AI agent, Claude 3.5 Sonnet (New) with open-source scaffolding, achieved only a 21.0% average replication score, while top ML PhD students achieved 41.4% on a subset of papers after 48 hours of work.
- PaperBench runs in three stages: agent rollout (creating a codebase), reproduction (executing the code in a fresh environment), and grading (evaluating results against the paper’s rubric).
- OpenAI has open-sourced the code and dataset to encourage further research into AI engineering capabilities.
My take: It won’t be many months until AI agents perform autonomous research better than humans, and we now have a pretty good way of tracking when that happens. The main question is how we will adapt to it. If an AI agent system is better than humans in writing research papers, where does that leave the researchers? How much will your list of published articles be worth, and how do you differentiate between bad and good researchers? And can current researchers do 10 times more research if they have the tools for it? My guess is that these systems will pass human researchers in terms of quality in around 2-3 years.
Read more:
- [2504.01848] PaperBench: Evaluating AI’s Ability to Replicate AI Research
- preparedness/project/paperbench at main · openai/preparedness · GitHub
CodeScientist: AI2 Introduces Autonomous Research System
https://allenai.org/blog/codescientist
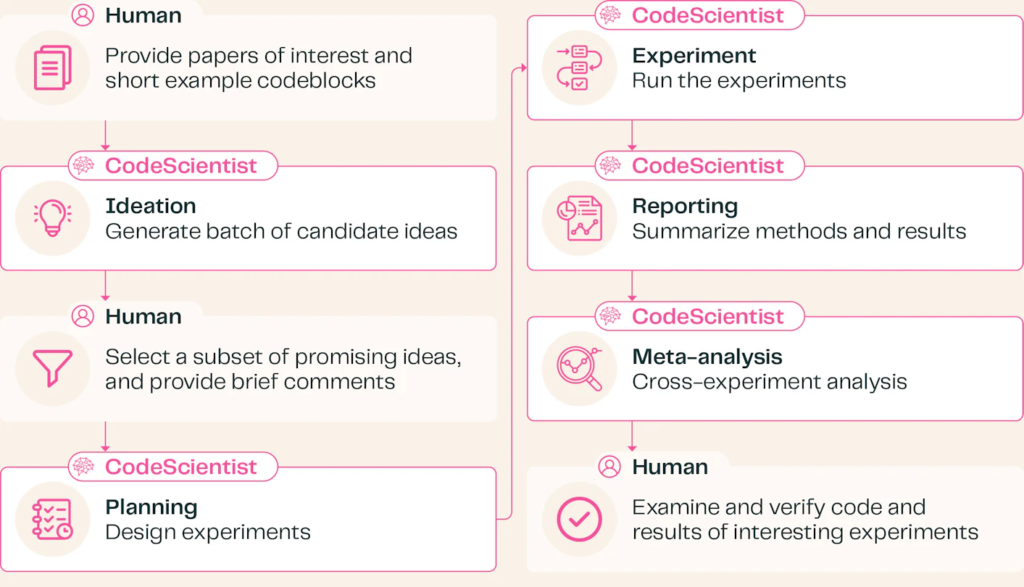
The News:
- Allen Institute for AI (AI2) has released CodeScientist, an AI system that conducts scientific experiments with minimal human guidance.
- The system identifies research gaps, forms hypotheses, designs experiments, writes code, and analyzes results through a structured five-step workflow.
- In initial testing, CodeScientist generated 19 potential discoveries in AI and virtual environments, with human experts validating six as scientifically novel and sound.
- Notable findings include insights about language models’ poor self-assessment abilities, benefits of simplified state representations, and advantages of stepwise environment generation.
- The system still faces practical limitations – more than half of its experiments fail due to debugging issues, requiring human oversight for quality control.
My take: Three weeks ago I wrote about Sakana’s AI Scientist, which generated the world’s first peer-reviewed scientific publication. CodeScientist from Allen AI is very similar, and clearly shows that this is an area that will grow in focus in the coming years as language models become better at working autonomously. If you are working as a researcher today, I would recommend you to start using these system just to get a feeling for them. Even if you find that they are not good enough for your specific use cases today, they will be shortly, and by using them regularly you will get a feeling for approximately when they will be good enough for everyday use. And once they get there they will change your daily job completely.
Anthropic Launches Claude for Education with Learning Mode for Universities
https://www.anthropic.com/news/introducing-claude-for-education
The News:
- Anthropic has introduced Claude for Education, a specialized version of its AI assistant designed specifically for higher education institutions, enabling universities to implement AI across teaching, learning, and administrative functions.
- The platform features a new “Learning Mode”, which guides students’ reasoning process rather than providing direct answers, using Socratic questioning to develop critical thinking skills and offering templates for research papers and study guides.
- Northeastern University, London School of Economics, and Champlain College have already signed full-campus agreements, with Northeastern providing Claude access to 50,000 students, faculty, and staff across 13 global campuses.
- The service includes administrative tools that can analyze enrollment trends, automate email responses to common inquiries, and convert complex policy documents into accessible formats.
My take: My kids use ChatGPT on a daily basis for most of their homework, and having access to Claude across entire universities is probably a good thing. It democratizes learning and makes the playfield more even, especially for those without study friends or families to help them out. I really like the new learning mode Anthropic introduced here, and I hope we soon get something similar in ChatGPT and the regular version of Claude.
GPT-4.5 Passes Turing Test, Convincing Humans It’s Human 73% of the Time
https://arxiv.org/html/2503.23674v1
The News:
- UC San Diego and MIT researchers conducted a comprehensive Turing test study with over 1,000 conversations, finding that OpenAI’s GPT-4.5 was judged to be human 73% of the time – significantly more often than actual humans were identified as human.
- The study used a three-party Turing test format where participants engaged in five-minute simultaneous conversations with both a human and an AI, then had to determine which was which.
- GPT-4.5’s success was heavily dependent on prompting – when given a “PERSONA” prompt instructing it to adopt the personality of an introverted, young person knowledgeable about internet culture, its success rate jumped from 36% to 73%.
- The research evaluated four AI systems in total: GPT-4.5, GPT-4o, Meta’s Llama 3.1-405B, and ELIZA (a 1960s chatbot), which achieved success rates of 73%, 21%, 56%, and 23% respectively.
- The study was methodologically robust, involving 284 participants across two independent populations (UCSD undergraduates and Prolific workers) in randomized, controlled, and pre-registered experiments.
My take: So we now have language models that people believe to be more human than regular humans. Let that sink in for a while, and imagine how this can and will be used by AI agents and automated callers in the near future. We quickly need new forms of identification systems, some sort if digital identity that shows on your phone who the caller is and that it is a real person and not an AI generated persona. I would not be surprised if Apple added this in their next iOS version coming later this year.
Read more:
- Large Language Models Pass the Turing Test
- The Turing Test has a problem – and OpenAI’s GPT-4.5 just exposed it | ZDNET
Google DeepMind Outlines Responsible AGI Development Framework
https://deepmind.google/discover/blog/taking-a-responsible-path-to-agi
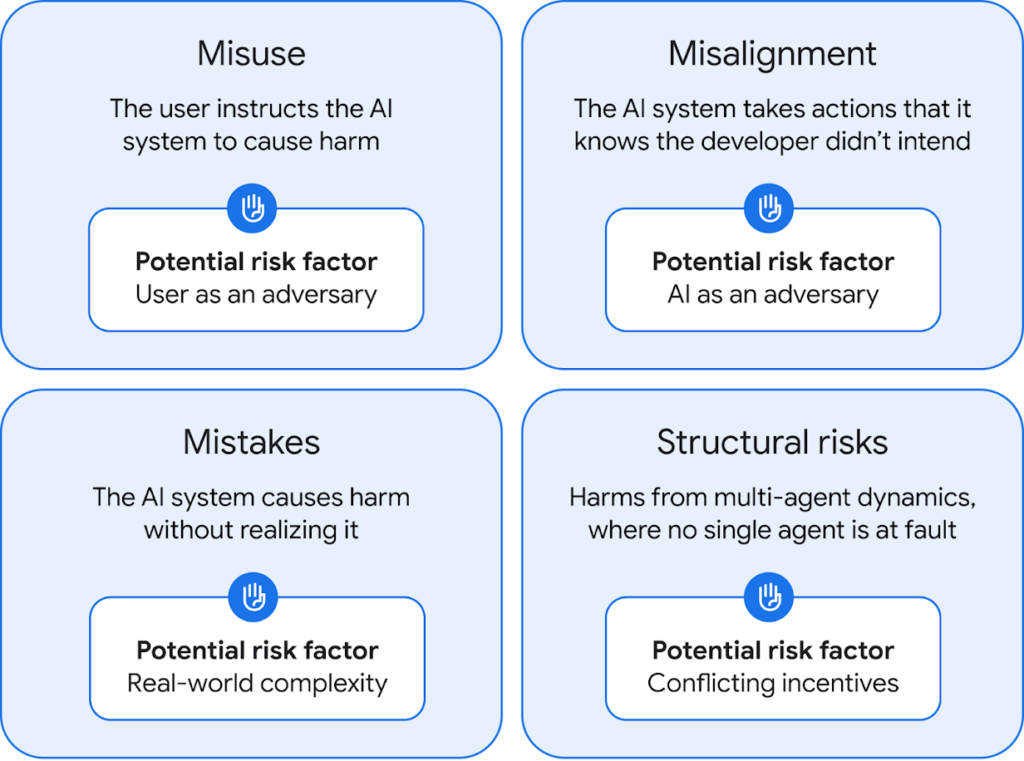
The News:
- Google DeepMind released a comprehensive 145-page paper on Artificial General Intelligence (AGI) safety and security, establishing a framework for responsible development as AGI becomes increasingly feasible.
- The framework identifies four main risk categories: deliberate misuse by humans, misalignment (AI taking unintended actions), mistakes (accidental harm), and structural risks (harmful interactions between AI systems).
- DeepMind’s approach integrates safety protocols from the earliest development stages rather than retrofitting them later, creating a “safety-by-design” methodology.
- The company has established an AGI Safety Council led by Co-Founder Shane Legg to analyze risks and recommend safety measures, working alongside their Responsibility and Safety Council.
- DeepMind is actively collaborating with nonprofit AI safety research organizations like Apollo and Redwood Research, and has launched an educational course on AGI safety for students and professionals.
My take: So, who will read through this extensive 145 page report on AGI safety and security? Not many, but it serves the purpose of establishing Google DeepMind in a leadership position in responsible AGI development. Google used the foundation of this work to build the free “Google DeepMind AGI Safety Course” available on YouTube, which is easier to digest than the full paper. Most industry experts seem aligned that we will get AGI within a few years, and depending on the pace of innovation it might take anywhere between 3-10 years to get there, with the average expectancy around 5 years in 2030. This means that within five years an AI will be able to do anything a human can do in front of a computer. And with the incredible speed of robot development, we should also have robots that physically can do any task a human can do but faster, with more precision, and working 24 hours every day with no rest. I think everyone will agree that letting these system loose in society without any kind of safety protocols is a bad idea, so it’s great to see the investment Google is doing in this area to get the right mindset and safety protocols in place when we are getting closer to fully autonomous and “smart” AI systems.
Read more:
Midjourney V7 Launches After Long Wait, Still Struggles with Hands
https://docs.midjourney.com/hc/en-us/articles/32199405667853-Version

The News:
- Midjourney just released Version 7, its first major update in nearly a year, featuring improved image quality, faster rendering speeds, and new personalization features.
- The new model renders images 20-30% faster than V6, with a new “Draft Mode” that generates images 10x faster at half the cost (though at lower quality).
- V7 introduces enhanced textures, better coherence in generating bodies and objects, and a personalization system that tailors results after users rate approximately 200 images.
- Despite improvements in realism, many users report persistent issues with hand rendering, including missing fingers, extra fingers, and distorted shapes – problems that were supposedly addressed in previous versions.
My take: If you want to create moody cinematic shots in a very specific art style, then Midjourney is probably still a good choice. Before you even start using v7 you need to personalize it with your own profile, which means you can clearly steer it in one specific direction when it comes to style. When it comes to image quality and realism it’s OK but not great. Here’s a thread on X with “10 wild examples of Midjourney v7” but I think they all look very synthetic and not at all realistic. When Midjourney v6 launched in December 2023 it was way ahead of it’s time, now it’s falling behind rapidly much due to large models like GPT-4o and Gemini 2 gaining full multimodal output capabilities which seems to be a key driver for realistic and detailed output. This release was not what Midjourney fans were hoping for.
Read more: