
The wildfires in Los Angeles this year are predicted to have cost over $250 billion, becoming one of the worst natural disasters in U.S. history. Current satellite systems like VIIRS and MODIS can detect fires quickly (within a few hours) but have problems identifying smaller fires (<100m²). Other systems like Sentinel-2 have details down to 10m² but with less frequent intervals (days rather than hours). Last week Google Research in partnership with Earth Fire Alliance, Muon Space, and the Gordon & Betty Moore Foundation, launched the first FireSat satellite, designed to detect wildfires as small as 5×5 meters in less than 20 minutes! The entire system is expected to be operational in 2030 with over 50 satellites, and the system uses advanced AI algorithms to compare current imagery with thousands of previous images of the same location, while factoring in local weather conditions. It’s hard to overstate the value of this system and the effect it might have on the lives of everyone, what an amazing achievement!
Google keeps improving their Gemini assistant, and just now they added the amazing Audio Overviews podcast feature directly to Gemini, so you can set it off to do a Deep Research and then get the results read back to you as a podcast. On your way to a meeting but want to know more about the client? Ask Gemini to do a Deep Research and then listen to the podcast show for 20 minutes on your way to the meeting. It was in October last year when Google did some major reshuffling of its Gemini team and made it a part of the DeepMind AI research lab at Google, led by the amazing Demis Hassabis. The pace of innovation at Google has skyrocketed since then, and the things they are putting out now are on a whole different level. They are still behind – Gemini still does not have a native desktop app, web search, or the full Gemini 2.0 Pro model available for chat, but I have no doubt they will catch up in all these areas during the year while pushing their models to the absolute state-of-the-art.
Thank you for being a Tech Insights subscriber!
THIS WEEK’S NEWS:
- AI-Powered Weather System ‘Aardvark’ Transforms Forecasting Without Supercomputers
- Google Launches FireSat Satellite to Detect Wildfires from Space
- OpenAI Launches Next-Gen Audio Models for Developers
- Roblox Launches Cube: Open-Source AI System for 3D Object Generation
- Mistral Small 3.1: Open-Source AI Model Outperforms Closed-Source Competitors
- ByteDance Introduces DAPO: A New Reinforcement Learning Method for LLMs
- Stability AI Launches Stable Virtual Camera for 3D Video Generation
- Google NotebookLM Introduces Interactive Mind Maps for Visual Learning
- Google Launches Canvas and Audio Overview Features for Gemini AI
- Claude Gets Real-Time Web Search
- OpenAI Launches o1-pro in API: Premium AI Model at Premium Price
- OpenAI Enables PDF Processing in GPT-4o API
- OpenAI Sora Shifts to Unlimited Video Generation Model
- Nvidia Launches Llama Nemotron Open-Source Reasoning Models
AI-Powered Weather System ‘Aardvark’ Transforms Forecasting Without Supercomputers
https://www.nature.com/articles/s41586-025-08897-0

The News:
- Researchers from Cambridge University, the Alan Turing Institute, Microsoft Research, and the European Centre for Medium Range Weather Forecasting have developed Aardvark Weather, a fully AI-driven weather prediction system that delivers accurate forecasts without requiring supercomputers.
- The system can generate forecasts tens of times faster and uses thousands of times less computing power than traditional forecasting methods, completing predictions in minutes on a standard desktop computer rather than hours on specialized hardware.
- Even using just 10% of the input data of existing systems, Aardvark already outperforms the United States national GFS forecasting system on many variables and competes with forecasts that incorporate expert human analysis.
- The model takes raw observational data from satellites, weather stations, ships, and other sensors to produce both global and hyperlocal forecasts without requiring the complex multi-stage process of traditional systems.
- Aardvark’s flexibility allows it to be quickly adapted for specific industries or locations, such as predicting temperatures for African agriculture or wind speeds for renewable energy companies in Europe.
What you might have missed: University of Cambridge writes: “Aardvark can deliver accurate forecasts tens of times faster than current AI and physics-based forecasting systems” while Professor Richard Turner says “Aardvark is thousands of times faster than all previous weather forecasting methods”. Which one is it? It turns out both are correct. If you were to run Aardvark on a traditional supercomputer it would be thousands of times faster than traditional systems. But run it on a standard desktop PC and it’s still 10 times faster. This is why you see different news outlets reporting different figures about Aardvark.
My take: It’s hard to overstate the importance of this research. “Aardvark reimagines current weather prediction methods offering the potential to make weather forecasts faster, cheaper, more flexible and more accurate than ever before, helping to transform weather prediction in both developed and developing countries”, says Professor Richard Turner from Cambridge’s Department of Engineering, who led the research. “Aardvark is thousands of times faster than all previous weather forecasting methods”.
Aardvark runs on standard computers, is thousands of times faster than all previous prediction models, and will be released open-source. This could have a massive effect on agriculture and renewable energy on a global scale. It’s such strange times we live in, where you almost get used to these “thousands of times faster” releases being announced almost every month now.
Google Launches FireSat Satellite to Detect Wildfires from Space
https://www.earthfirealliance.org/press-release/protoflight-launch

The News:
- Google Research, in partnership with Earth Fire Alliance, Muon Space, and the Gordon & Betty Moore Foundation, has launched the first FireSat satellite, designed to detect wildfires as small as 5×5 meters using AI.
- The satellite launched on March 14, 2025, via SpaceX’s Transporter-13 rideshare mission, marking the first step in a planned constellation of over 50 satellites that will provide global wildfire monitoring with updates every 20 minutes.
- FireSat uses AI to compare current imagery with thousands of previous images of the same location, while factoring in local weather conditions to accurately identify fires.
- The full FireSat constellation, expected to be operational by 2030, will provide near real-time global coverage of wildfires, with the next three satellites scheduled for launch in 2026.
- Google.org has provided $13 million in funding to support the initiative led by Earth Fire Alliance, a non-profit established specifically to launch and operate the FireSat constellation.
My take: Existing satellite systems provide either low-resolution imagery or infrequent updates, making early detection of fires very difficult. FireSat’s ability to detect small fires and provide updates every 20 minutes could significantly improve response times for firefighting agencies. Like Aardvark mentioned above, FireSat has the potential to significantly improve lives of many, and going from zero to full operation with 50 satellites in 5 years for this new system is almost unbelievably fast.
OpenAI Launches Next-Gen Audio Models for Developers
https://openai.com/index/introducing-our-next-generation-audio-models

The News:
- OpenAI released new API-based audio models for text-to-speech and speech-to-text, enabling more natural and customizable voice interactions.
- The gpt-4o-transcribe and gpt-4o-mini-transcribe models offer improved speech recognition accuracy, particularly in challenging scenarios with accents, background noise, and varying speech speeds.
- The gpt-4o-mini-tts text-to-speech model allows developers to customize speaking styles through text instructions, such as “speak like a mad scientist” or “use a serene voice, like a mindfulness teacher”.
- Integration with the Agents SDK enables developers to convert existing text-based agents into voice agents with minimal code changes, rrequiring only nine lines of additional code.
My take: If you just quickly try some of the examples posted online the quality of this new model seems to be ok but not great. But if you dig a bit deeper you’ll quickly find out that the model is promptable, which means that if you ask it to pronounce things a certain way it will understand what you ask and do that. This means you can even prompt it to express emotions, like “do a mad scientist voice” or “Tone: Screaming very loudly, Emotion: Very very angry, Delivery: Loud”.
The models also feature a new property called “Semantic VAD”, or Semantic Voice Activity Detection, which “chunks the audio up based on when the model thinks the user’s actually finished speaking”. This means the model tries to understand the meaning of speech, not just detecting silence, which is a big step forward towards avoiding models interrupting you mid-thought.
Finally, the models are relatively cheap to use. OpenAI’s TTS costs $0.015 per 1,000 characters, with their premium TTS HD option at $0.030 per 1,000 characters. ElevenLabs as a comparison costs $0.18 per 1,000 characters (Scale plan), making OpenAI six times cheaper than ElevenLabs’ most discounted tier.
Roblox Launches Cube: Open-Source AI System for 3D Object Generation
https://github.com/Roblox/cube

The News:
- Roblox has released Cube 3D, an open-source foundational model that generates 3D objects from text prompts.
- The first feature available is mesh generation, allowing developers to create 3D representations of objects with simple prompts like “generate an orange racing car with black stripes,” currently in beta and available this week.
- Cube 3D learns from actual 3D models (meshes, geometries, and their properties) during its training process, instead of learning from 2D images and then trying to convert them to 3D. This means the AI analyzes complete three-dimensional structures with all their spatial information intact, resulting in more accurate and functional 3D objects that work properly in games.
- The model uses a novel 3D tokenization technique, representing 3D objects as tokens similar to how language models process text, allowing it to predict the next shape to complete a 3D object.
- Future plans include expanding Cube to generate more complex objects, full scene generation, and developing a multimodal model that accepts text, images, and video inputs, along with additional AI tools for text generation, text-to-speech, and speech-to-text capabilities.
My take: Last year I wrote about Hunyuan3D and Meta 3D Gen which were then state-of-the-art for asset 3D generation. But both Hunyuan3D and Meta 3D are optimized for meshes that look visually good but have lots of topographical problems that make them quite bad for game development. If you have tried using them to create assets for a prototype game you know what I mean. Cube3D is different since it’s directly trained on how actual 3D models are designed, which should potentially result in more useful meshes. For many aspiring game developers this could be exactly what you have been waiting for!
Mistral Small 3.1: Open-Source AI Model Outperforms Closed-Source Competitors
https://mistral.ai/news/mistral-small-3-1
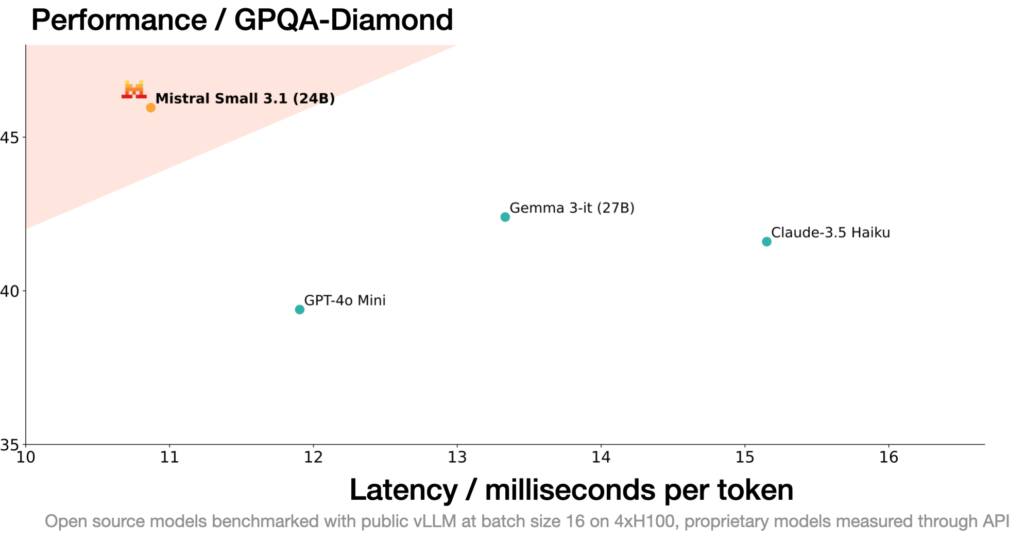
The News:
- Mistral AI has released Mistral Small 3.1, a 24 billion parameter AI model that delivers multimodal capabilities, multilingual support, and improved text performance under an Apache 2.0 license!
- The model features a 128k token context window and processes 150 tokens per second, running efficiently on consumer hardware like a single RTX 4090 GPU or a Mac with 32GB RAM.
- A few select benchmark tests show Mistral Small 3.1 outperforming comparable models including Google’s Gemma 3 (27B), OpenAI’s GPT-4o Mini, and Anthropic’s Claude 3.5 Haiku across text understanding, reasoning, and multimodal tasks.
My take: On paper this model looks amazingly good. Lowest latency of all smaller models, but with performance that beats Gemma 3 (instruction tuned model) on several benchmarks. In threads on Reddit however people report mixed results with Mistral Small 3.1, where many say it “performs about the same as the original Mistral Small 3”. Another thread (which also posted the YouTube video below) says that Mistral was unique in that it got 0 hallucinations in their RAG test, which Gemma 3 stumbled on. As usual, don’t pick a model based on benchmarks but always evaluate several models based on your use cases. If you need a small model that can run on your 4090 PC then you should definitely try this one out!
Read more:
ByteDance Introduces DAPO: A New Reinforcement Learning Method for LLMs
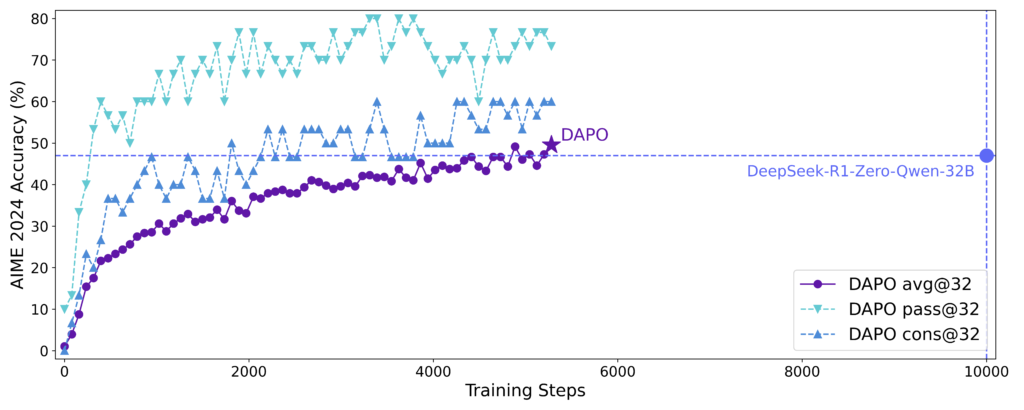
The News:
- ByteDance, creator of TikTok, has introduced DAPO (Decoupled Clip and Dynamic sAmpling Policy Optimization), a new reinforcement learning system for Large Language Models (LLMs) that requires 50% fewer training steps compared to previous methods like DeepSeek’s GRPO.
- DAPO achieved 50 points on the American Invitational Mathematics Examination (AIME) 2024 using the Qwen2.5-32B base model and is fully open-sourced, including algorithmic details, training procedures, and datasets.
- The system incorporates four key innovations: Clip-Higher, Dynamic Sampling, Token-level Policy Gradient Loss, and Overlong Reward Shaping.
My take: This looks like a significant advancement in reinforcement learning for LLMs, which could lead to faster iteration cycles and reduced computational costs for developing advanced language models. DeepSeek’s GRPO was already leading the way here, and now we have a new method that requires 50% less training steps. And released as fully open-source. What an amazing release by ByteDance!
Read more:
- X: New RL Method thats better than GRPO! 🤯
- Arxiv: DAPO: An Open-Source LLM Reinforcement Learning System at Scale
- GitHub: DAPO
Stability AI Launches Stable Virtual Camera for 3D Video Generation
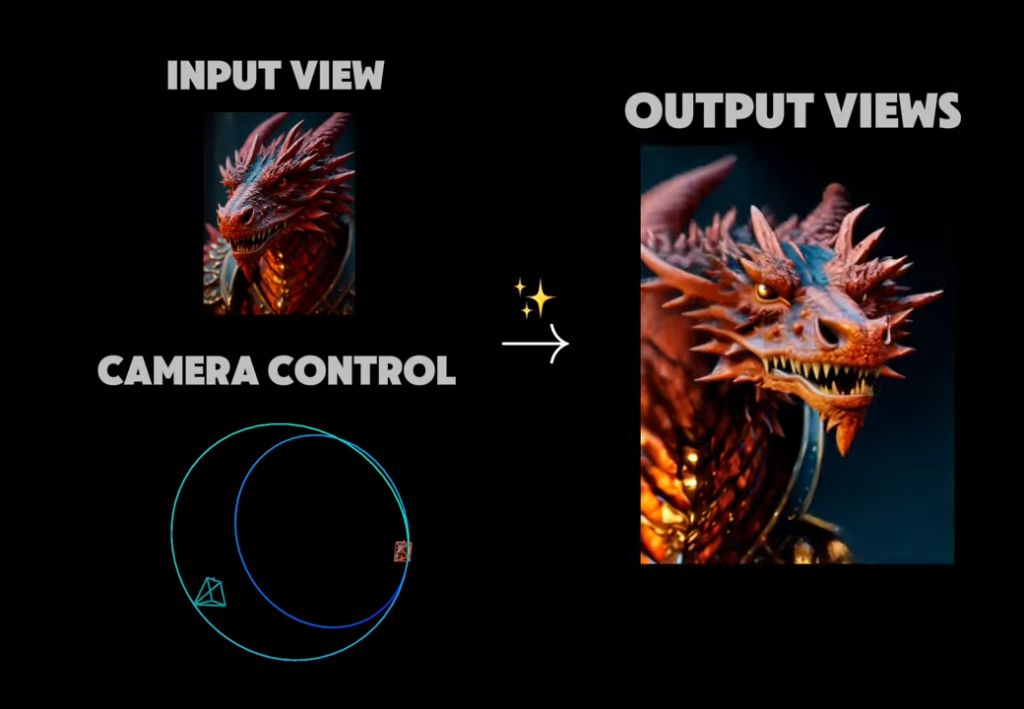
The News:
- Stability AI has released Stable Virtual Camera, a multi-view diffusion model that transforms 2D images into immersive 3D videos with realistic depth and perspective, without requiring complex reconstruction or specialized skills.
- The model can generate 3D videos from a single image or up to 32 images, following user-defined camera trajectories or 14 preset dynamic camera paths including 360°, Spiral, Dolly Zoom, Move, Pan, and Roll.
- It supports multiple aspect ratios (1:1, 9:16, 16:9) and can generate videos up to 1,000 frames long while maintaining 3D consistency.
- The technology outperforms existing models in Novel View Synthesis benchmarks but may produce lower-quality results with images featuring humans, animals, or dynamic textures like water.
- Stable Virtual Camera is available for research use under a Non-Commercial License, with code on GitHub and model weights on Hugging Face.
My take: Take a few images, define how you want the camera to move, and voilà you have a 3D camera moving around in a 3D scene. Even if the render quality is not ready for cinematic movies, I can definitely see it being widely used for social media and storyboard work where you want to evaluate different camera movements quickly to see how they match up with each other. If you have 1 minute their official tech demo video is worth your time!
Read more:
- Stable Virtual Camera | Tech Demo – YouTube
- Arxiv: Stable Virtual Camera: Generative View Synthesis with Diffusion Models
- GitHub : Stable Virtual Camera: Generative View Synthesis with Diffusion Models
Google NotebookLM Introduces Interactive Mind Maps for Visual Learning
https://www.maginative.com/article/google-adds-interactive-mind-maps-to-notebooklm
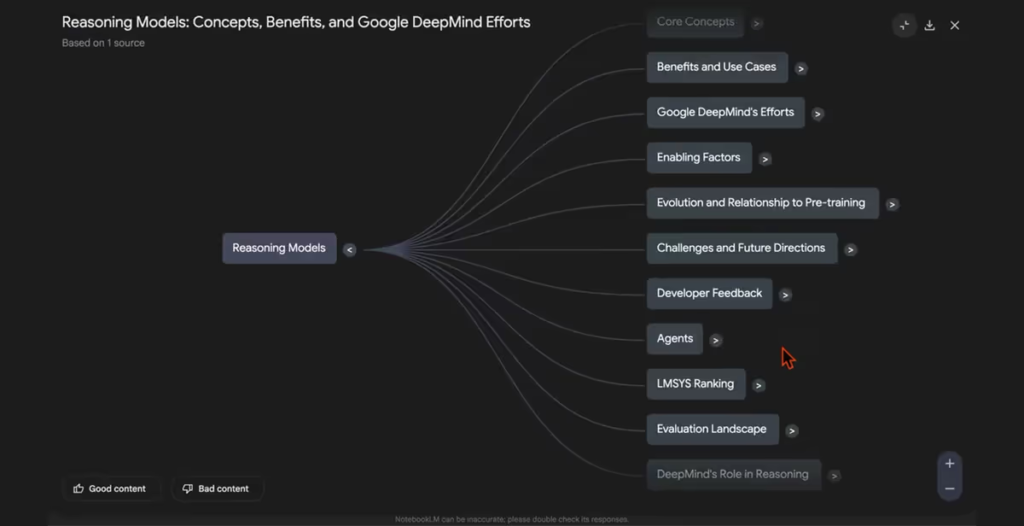
The News:
- Google just added Interactive Mind Maps to NotebookLM, making it possible to visualize complex information from uploaded sources as branching diagrams that organize key concepts hierarchically.
- The feature transforms notes into visual, interactive maps where users can expand nodes to reveal subnodes, navigate complex topics quickly, and click directly on nodes to ask specific questions about those concepts.
- The rollout began on March 19, 2025, with Google promising full availability within two weeks for both free and paid NotebookLM users across 180+ regions.
My take: I really love NotebookLM. The audio podcast feature, YouTube video summary feature, and now mind map feature makes this an amazing tool for quickly browsing and learning from large amounts of information! If you are a student or researcher and have not yet tried NotebookLM, definitely do that, it will save you so much time!
Read more:
Google Launches Canvas and Audio Overview Features for Gemini AI
https://blog.google/products/gemini/gemini-collaboration-features
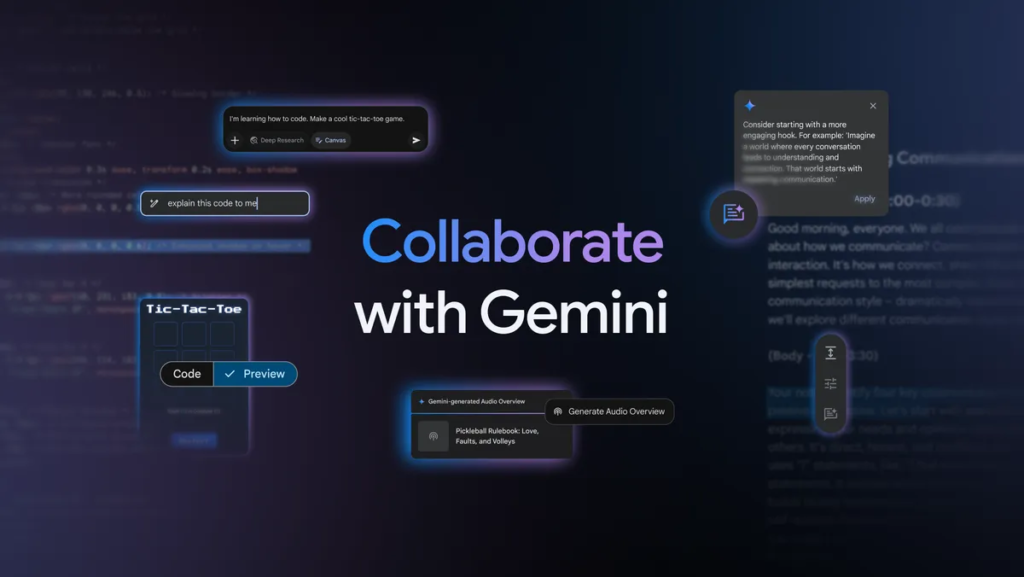
The News:
- Google introduced two new features Canvas and Audio Overview to Gemini AI.
- Canvas provides an interactive workspace for real-time collaboration on documents and code, allowing users to write, edit, and refine their work.
- Audio Overview converts documents, slides, and reports into AI-generated podcast-style audio discussions, summarizing content and providing unique perspectives.
- Audio Overview is currently available in English for Gemini and Gemini Advanced users, with plans to expand to more languages.
My take: Having Deep Research automatically generating a podcast episode might be enough to make me want to switch to Gemini for Deep Research. I use Deep Research when I’m on my way to client meetings to get up to speed on their business. Being able to listen to a personalized podcast show in my car on the way to the meeting would be amazing. Have you tried Audio Overview with Deep Research, I would love to hear your comments on this one!
Claude Gets Real-Time Web Search
https://www.anthropic.com/news/web-search
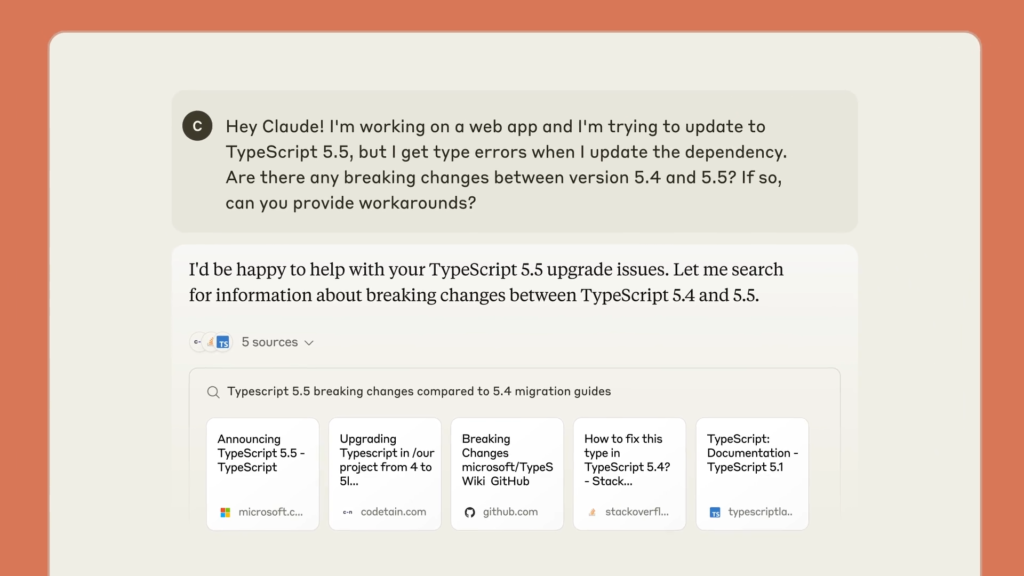
The News:
- Anthropic just added web search capabilities to Claude. The feature is currently available as a preview for paid Claude users in the United States, with plans to expand to free users and additional countries soon.
- Web search works exclusively with Claude 3.7 Sonnet and can be activated by toggling it on in profile settings within the Claude web app.
- Like other models with web search, Claude provides direct citations and source links, allowing users to verify information and fact-check responses.
What you might have missed: Claude seems to be using Brave for searches. While they don’t mention it themselves on their web page, Claude itself reports back that it uses Brave since its web_search function takes a parameter called “BraveSearchParams”.
My take: We now have ChatGPT that browses the web with Bing, Claude that browses the web with Brave, and Perplexity that uses their own search index. None of these search engines are my favorite for finding information quickly and efficiently here in Sweden. Google is keeping Google Search exclusively for Gemini, and I think it’s way too early to announce the “death of Google search”. Google Search is already evolving with the new “AI Mode”, and when it comes to search – if you have the best platform, people will use it. Once Google gets their AI Mode Search ready for a full-scale rollout this could be one of the biggest threats to OpenAI and Claude, why go the extra route to chatgpt.com or claude.ai when you can just ask anything in the search bar directly in your browser?
OpenAI Launches o1-pro in API: Premium AI Model at Premium Price
https://techcrunch.com/2025/03/19/openais-o1-pro-is-its-most-expensive-model-yet/
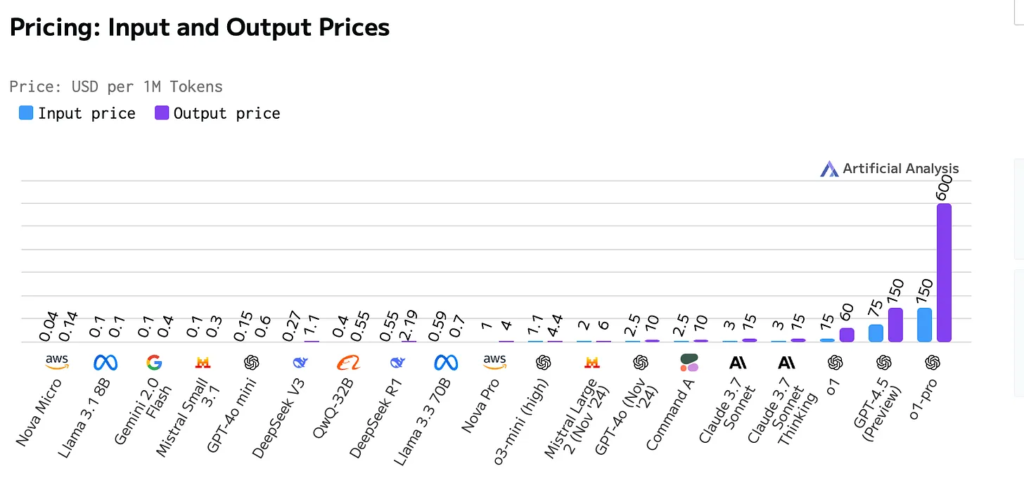
The News:
- OpenAI released o1-pro through their API, an advanced version of its o1 reasoning model, now available to select developers at significantly higher pricing than previous models.
- The model costs $150 per million input tokens and $600 per million output tokens, which is twice the price of GPT-4.5 for input and ten times more expensive than the regular o1 model.
- O1-pro features a 200,000 token context window, supports image inputs, and offers 100,000 max output tokens with a knowledge cutoff date of October 1, 2023.
- Access is currently limited to developers who have spent at least $5 on OpenAI API services, targeting those working on AI agents requiring reliable reasoning capabilities.
- Internal benchmarks show o1-pro is slightly more capable and reliable in solving math problems and executing coding tasks than the standard o1 model.
My take: I’m not really sure who is willing to pay $150 for one million input tokens for slightly better performance than o1, but maybe there is a market for this. These prices just makes it even more clear that we need new and better hardware for inference, and we need it quickly.
OpenAI Enables PDF Processing in GPT-4o API
https://platform.openai.com/docs/guides/pdf-files

The News:
- OpenAI has added PDF processing capabilities to its GPT-4o API, allowing developers to input PDF files directly.
- The system extracts both text and images from each page, enabling the model to understand and respond directly to PDF content.
My take: This was quite a small announcement last week but it’s a pretty big announcement for anyone working with PDF documents and GPT-4o. Previously you needed to preprocess PDF files to extract text before sending the documents to GPT-4o, which typically involved using optical character recognition tools (OCR) to convert PDF content into plain text, but now you can send it PDF files directly. This is not a competitor for Mistral OCR which I wrote about two weeks ago (which converts PDF files into markdown), but more of an easier way to quickly process PDF documents for one-off processing for specific prompts.
OpenAI Sora Shifts to Unlimited Video Generation Model
https://help.openai.com/en/articles/9957612-generating-videos-on-sora
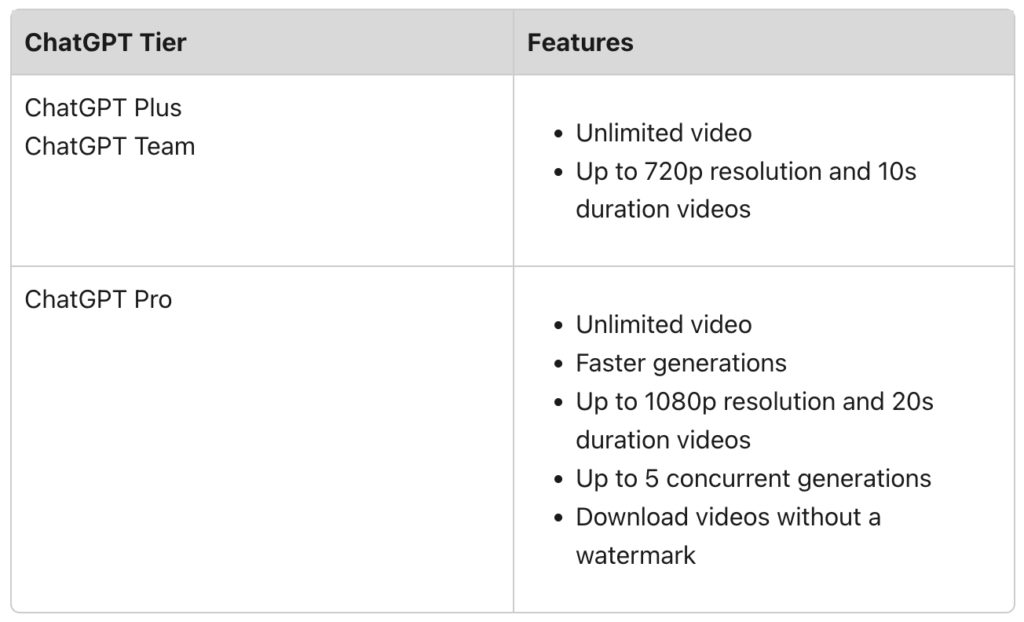
The News:
- OpenAI just removed the credit-based system for its Sora text-to-video AI generator, now offering unlimited video generations across all paid subscription tiers.
- The change affects both ChatGPT Plus ($20/month) and ChatGPT Pro ($200/month) subscribers, eliminating the previous limits of 50 and 500 priority videos per month respectively.
- ChatGPT Plus users still face restrictions on video quality (720p), length (5 seconds) and can only download watermarked videos, while Pro subscribers ($200/month) maintain access to higher quality 1080p resolution, 20-second length and watermark-free videos.
My take: I remember when Sora first was announced on February 15, 2024, and wow what a huge improvement in AI-generated video quality it was from what we had back then! Over the past year however we have seen some amazing innovations in video generation from companies like Kling AI, Pika Labs, Adobe, ByteDance, Luma Labs and Google all while Sora seems to be stuck at the same point as when it launched a year ago. The best video generator now is undoubtedly Google Veo 2, but it’s still not available in Europe. So if you live in the EU and have an OpenAI Pro subscription, Sora might be your best choice for AI video generation today.
Nvidia Launches Llama Nemotron Open-Source Reasoning Models
https://www.nvidia.com/en-us/ai-data-science/foundation-models/llama-nemotron

The News:
- Nvidia released the Llama Nemotron family of open-source reasoning models to accelerate enterprise adoption of agentic AI for complex problem-solving.
- The models offer on-demand reasoning capabilities with up to 20% improved accuracy and 5x faster inference compared to base models and are available in three sizes: Nano (8B parameters) for edge devices, Super (49B) for single GPUs, and Ultra (253B) for multi-GPU setups.
My take: The Nemotron models are built specifically for agentic AI workflows. They are built on Meta’s Llama models and then distilled through Neural Architecture Search to reduce size, followed by supervised fine-tuning and and reinforcement learning. If you want a model to generate large amounts of code and text these models are not for you, but if you want models with very strong agentic performance that can run well on single-GPU systems then you should definitely check these ones up.