
Will you use Google Search in 2026 the same way you have been using it over the past two decades? I am quite sure the answer is no. I am a firm believer in agentic search, and I believe it will change everything about how we store and publish information online. Last week Andrej Karpathy wrote on X: “It’s 2025 and most content is still written for humans instead of LLMs. 99.9% of attention is about to be LLM attention, not human attention”. This should be your focus going forward with everything you create. When you design a web page, make sure it’s designed for AI search bots. When you publish a report, write it in markdown and publish both documents online. “Docx” Word files are useless in this future. There is a huge opportunity here for new players to challenge the status quo of Office documents in native formats and web pages with more JavaScript than content. Once the transition to search agents has started for real, you can bet that the entire web will look completely different than what we are used today.
Last week Google launched some amazing new innovations. First they announced two new Gemini Robotics AI models based on Gemini 2.0 that adds physical actions as a new modality to Gemini! This means that Gemini 2.0 can now hear, see and interact with its surroundings. Google also launched Gemma 3, an new model that can run on a single GPU but with performance matching the world’s top closed source models! What’s even better, it’s free to use commercially! The third release Native Image generation is one of the most amazing things I have seen this year, so I’ll just stop writing now: go watch their launch video called Building with Gemini 2.0: Native image output! It’s just 3 minutes long, and I promise that you have never seen anything like it before! Then come back here and read the rest. Trust me, it’s worth it! 🤯
Thank you for being a Tech Insights subscriber!
THIS WEEK’S NEWS:
- Google DeepMind Introduces Gemini Robotics Models for Physical World AI
- Google Releases Gemma 3: The World’s Most Capable Single-GPU AI Model
- Google Launches Native Image Generation with Gemini 2.0 Flash
- Google Makes Deep Research Available to All Users
- Google AI Studio Adds Support for YouTube Video Analysis
- AI-Generated Paper Passes Peer Review at ICLR 2025 Workshop
- Sesame Releases CSM-1B Voice Model as Open Source
- OpenAI Launches New Agents SDK and Responses API for Building AI Agents
- Cohere Launches Command A: Enterprise-Grade AI Model Requiring Just 2 GPUs
- Microsoft Announces Copilot for Gaming, AI Assistant for Xbox Players
- EuroBERT: A New Family of Multilingual Encoder Models
Google DeepMind Introduces Gemini Robotics Models for Physical World AI
https://deepmind.google/discover/blog/gemini-robotics-brings-ai-into-the-physical-world

The News:
- Google DeepMind just launched two new AI models based on Gemini 2.0 that enable robots to perform a wider range of real-world tasks: Gemini Robotics and Gemini Robotics-ER.
- Gemini Robotics is an advanced vision-language-action (VLA) model that adds physical actions as a new output modality, allowing direct robot control with more than double the performance of other leading VLA models on generalization benchmarks.
- Gemini Robotics-ER focuses on advanced spatial understanding, enabling robotic engineers to run their own programs using Gemini’s embodied reasoning capabilities.
- The models excel in three key areas: generality (adapting to new situations), interactivity (responding to natural language commands and environmental changes), and dexterity (performing precise tasks like origami folding or packing items into Ziploc bags).
- Google DeepMind is partnering with Apptronik to build humanoid robots with Gemini 2.0, and working with testers including Agile Robots, Agility Robotics, Boston Dynamics, and Enchanted Tools.
My take: If you have 3 minutes go watch their official launch video, it’s really great and gives you a very good insight into our robotics future where language models have eyes, ears and hands!
Just a few months ago Google launched ALOHA Unleashed (Tech Insights 2024 week 38), and it makes you wonder what they did to make their robotics system this much better in such a short time? Well their new vision-language-action (VLA) model built on Gemini 2.0 is now in full control of the robot system, translating visual inputs and language commands into physical movements. Carolina Parada, DeepMind’s senior director and head of robotics, explained this as the model “draws from Gemini’s multimodal world understanding and transfers it to the real world by adding physical actions as a new modality”. You can look at it like Gemini 2.0 suddenly got a pair of hands and knows how to use them.
Kanishka Rao, director of robotics at DeepMind, says that “One of the big challenges in robotics, and a reason why you don’t see useful robots everywhere, is that robots typically perform well in scenarios they’ve experienced before, but they really failed to generalize in unfamiliar scenarios”. Well now we have a solution for that, and it won’t be long until we will have robots doing everything we can do with our hands but with much higher precision and way faster. Think about that for a while, and how it will affect things in the near future.
Read more:
Google Releases Gemma 3: The World’s Most Capable Single-GPU AI Model
https://blog.google/technology/developers/gemma-3
The News:
- Last week Google launched Gemma 3, a family of open AI models designed to run on a single GPU or TPU.
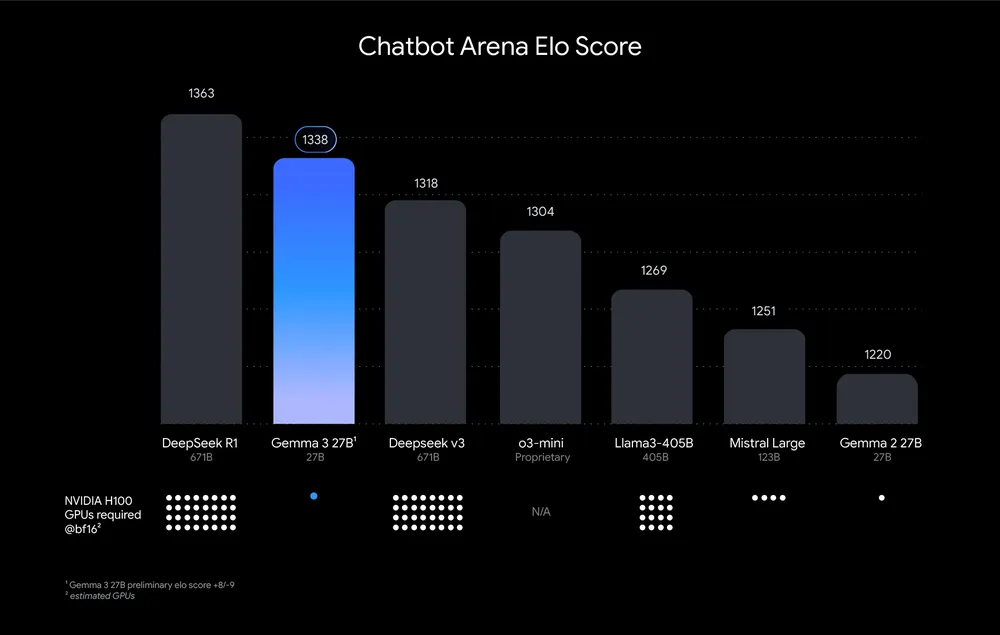
- The model comes in four sizes (1B, 4B, 12B, and 27B parameters) and outperforms larger competitors like Llama-405B, DeepSeek-V3, and OpenAI’s o3-mini in preliminary human preference evaluations on LMArena’s leaderboard.
- Gemma 3 features a 128K-token context window, supports over 35 languages out-of-the-box with pre-trained support for over 140 languages, and can process text, images, and short videos.
- The model achieves 98% of DeepSeek R1’s Elo score (1338 versus 1363) while using only one NVIDIA H100 GPU compared to R1’s estimated 32 GPUs.
My take: Google announced that Gemma has been downloaded over 100 million times the past year since the first version was launched, and over 60,000 Gemma variants have been created by users. The Gemma 3 models are built from the same technology as Gemini 2.0, but are designed to run directly on devices. The “Elo Score” user ranking is very close to DeepSeek R1, which is amazing considering R1 requires 32 NVIDIA H100 GPUs to run. Like DeepSeek, Gemma 3 is also free to use commercially. If you have considered local models but have been put off by the relatively poor performance of Gemma 2 or expensive hardware requirements of models like Llama3 and DeepSeek R1, you now have an amazing free choice in Gemma 3 27B. Truly amazing work Google!
Read more:
Google Launches Native Image Generation with Gemini 2.0 Flash
https://developers.googleblog.com/en/experiment-with-gemini-20-flash-native-image-generation

The News:
- Google released native image generation capabilities in Gemini 2.0 Flash, allowing users to create and edit images directly within the language model rather than routing requests to separate diffusion models like DALL-E or Imagen.
- The feature is currently available for free in Google AI Studio and through the Gemini API for developers, with plans to release it to all Gemini users in the near future.
- Unlike traditional AI image generators, Gemini 2.0 Flash maintains consistency across multiple images, enabling users to create visual stories with consistent characters and settings or make iterative edits through natural language dialogue.
- The model excels at rendering text within images, addressing a common limitation in other AI image generators that often produce illegible or misspelled text.
- Users can upload existing images and modify them with simple prompts like “add sunglasses” or “add chocolate drizzle,” with the model preserving the original image’s context and making precise edits in seconds.
My take: This one of the most amazing releases I have seen this year. Take any image. Then describe in words what you want Gemini 2.0 to do with it. Change hair style. Change clothes. Change background. Add a dragon. Type anything and Gemini 2.0 will change it as you like. Also, ask it to write a story with images, and the images will keep a consistent look. I don’t really know what to say, other than maybe Photoshop and Lightroom will be seen as relics of the past in a year or so. Here’s their launch video, go watch it, it’s just 3 minutes long.
Read more:
- Google’s Gemini 2.0: AI Image Generation & Editing is INSANE! – YouTube
- Building with Gemini 2.0: Native image output – YouTube
Google Makes Deep Research Available to All Users
https://blog.google/products/gemini/new-gemini-app-features-march-2025
The News:
- Google made its Gemini Deep Research tool available to all users for free last week.
- Free users can try Deep Research “a few times a month” in more than 45 languages, while Gemini Advanced subscribers continue to receive expanded access.
- Aarush Selvan, senior product manager at Google, says “We’re looking at the kinds of tasks where before you might have had to open 50 Chrome tabs and weave together information to get to an answer, or to go really deep on a topic. This new model is actively thinking between taking steps”, says Selvan. “That allows it to be more thoughtful in how it browses the web and to do more analysis on its findings. The idea is it will start being able to write more insightful and more detailed reports”.
My take: We now have OpenAI Deep Research, Google Deep Research, Perplexity Deep Research, DeepSeek, and a whole lot more to choose from. Personally I tend to switch between OpenAI and Perplexity, where I use OpenAI Deep Research if I want the best quality and can afford to wait a few minutes, or Perplexity if I just want it to search around dozens of web pages quickly and get near instant results. Perplexity does have a tendency to hallucinate or misinterpret the content though, so just be aware of that if you try it out (OpenAI and Google seems to be much better at minimizing hallucinations).
Google AI Studio Adds Support for YouTube Video Analysis
https://twitter.com/OfficialLoganK/status/1899914266062577722
The News:
- Google has officially added support for processing YouTube video links directly in Google AI Studio and through the Gemini API, enabling users to analyze and summarize video content without manual downloading.
- Previously, users had to download YouTube videos as MP4 files and upload them to Gemini 1.5 Pro, but now the process can be streamlined by simply passing the YouTube URL.
My take: Wow, there are so many things to do with this! You can now create an AI agent that subscribes to your top YouTube content creators, summarizes their latest videos once they are posted, then sends you a quick summary if it’s worth watching them or not. Or build an agent that compares your competitor videos to your videos and gives you suggestions for improvements! Some content creators will see this API as a big threat to their existence, while some will use it to attract more followers. I think one of the main use cases will be filming academic lectures, putting them online and then automatically creating lecture notes with timestamps and even presentation decks based on the video. So many possibilities!
AI-Generated Paper Passes Peer Review at ICLR 2025 Workshop
https://sakana.ai/ai-scientist-first-publication

The News:
- Sakana AI announced that a paper fully generated by their AI Scientist-v2 system passed peer review at an ICLR 2025 workshop, marking what they claim is the first AI-generated paper to pass standard scientific peer review.
- The AI system independently developed the scientific hypothesis, designed experiments, wrote code, conducted research, analyzed data, created visualizations, and authored the entire manuscript without human modifications.
- The accepted paper, titled “Compositional Regularization: Unexpected Obstacles in Enhancing Neural Network Generalization”, received an average score of 6.25 from reviewers, placing it above the acceptance threshold.
- Of three AI-generated papers submitted to the workshop, only one was accepted, with the experiment conducted with full cooperation from ICLR leadership and workshop organizers.
My take: We can all see where this is heading, but it’s difficult to grasp the full impact these AI agents will have once they become better than us humans at these tasks. When AI agents can write better articles than the best researchers, and AI agents can review papers better than the best reviewers, how will this affect the research community? How will we distinguish between good and bad researchers, if everyone with the right tools can produce amazing papers? We are not there yet, but remember that the first usable multimodal models came out less than a year ago (GPT-4o). Many researchers I know still continue working mostly like they have done in the past decade, with the exception that ChatGPT is typically involved in the early writing phases. If an AI can do all the difficult things like hypothesis generation, discussions, results summary, writing and report generation, either we need much less researchers or the researchers we have now can do much more research. Let’s hope for the latter!
Read more:
- Paper: Compositional Regularization: Unexpected Obstacles in Enhancing Neural Network Generalization
Sesame Releases CSM-1B Voice Model as Open Source
https://huggingface.co/sesame/csm-1b
The News:
- Sesame, the AI startup behind the viral voice assistant Maya, released its Conversational Speech Model (CSM-1B) under an Apache 2.0 license last week, making it available for commercial use with minimal restrictions.
- The 1-billion-parameter model generates audio from text and voice inputs using Residual Vector Quantization (RVQ) to encode and recreate human-like speech, similar to technology used in Google’s SoundStream and Meta’s Encodec.
- CSM-1B combines Meta’s Llama language model with an audio decoder to produce realistic speech, though it isn’t fine-tuned for specific voices and has limited capabilities with non-English languages.
- The model can run locally on consumer hardware, with tests showing it functions effectively on a laptop with an RTX 4060 and just 8GB of VRAM.
My take: A lot of people have raved over the Maya voice model the past weeks, but I thought it was still pretty meh and did not sound at all like talking to a real person. Anyway last week Sesame released their text-to-speech model as Open Source under the Apache 2.0 license, and you can now run it locally on your laptop if you want to. Remember this is just a part of their conversational voice system, so don’t expect that you will get something like the Maya voice assistant running just yet. Also this base model is not fine-tuned for any specific voice, so even if this is the technology that powers their “Maya voice model” don’t expect it to sound anything like Maya when you run it. And also, you need something like Gemma 3 (mentioned above) if you want to build a conversational agent with it.
Read more:
- Morgan Brown (VP Product at Dropbox): Sesame AI delivers lifelike, expressive speech that makes AI feel like a real presence
- Tobi Lutke (CEO Shopify): Sesame’s voice model is absolutely insane.
OpenAI Launches New Agents SDK and Responses API for Building AI Agents
https://openai.com/index/new-tools-for-building-agents
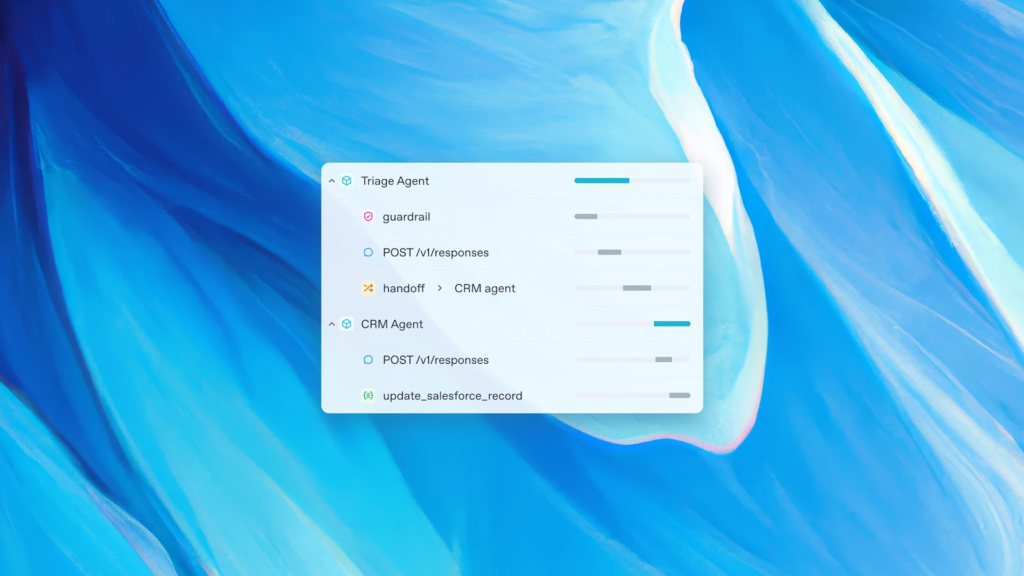
The News:
- OpenAI just released the Agents SDK and Responses API, designed to help developers build reliable AI agents that can independently accomplish complex tasks using reasoning and multi-modal interactions.
- The Responses API combines chat completions with assistant capabilities and includes built-in support for web search, local file search, and computer control using mouse and keyboard.
- The Agents SDK is an open-source framework that enables orchestration of agentic workflows by defining distinct agents, managing control transfers between them, implementing safety checks, and visualizing traces to observe agent behavior.
- The new tools support all current OpenAI models including o1, o3-mini, GPT-4.5, GPT-4o, and GPT-4o-mini, with web search models scoring 90% and 88% accuracy on the SimpleQA benchmark.
- OpenAI plans to deprecate the previous Assistants API by mid-2026, encouraging developers to transition to the new Responses API for future projects.
My take: I tested their new Agents SDK over the weekend, typing a prompt into Cursor and 20 minutes later I had a repo with 8 files and a working competitor-analysis AI agent, in total over 50kb of working Python source code. Every time I do something like this I just cannot see how anyone would prefer to NOT use AI for coding, just writing 50kb of text is difficult as it is. So, how does this new Agent SDK compare to other popular agent frameworks like LangGraph and Microsoft Autogen?
OpenAI Agents SDK is something I would recommend if you want rapid deployment of AI agents with minimal development overhead. You get things like built-in web search, built-in file search and computer use, all through a simple to use API. Here’s a tutorial on how to use it, it’s really straightforward.
LangGraph is something I would recommend for companies requiring complex, stateful applications with advanced workflows. Its graph-based architecture is great at maintaining conversation context and cyclical data flows, making it perfect for advanced chatbots and complex RAG (Retrieval-Augmented Generation) pipelines.
AutoGen is what I would recommend if you need collaborative multi-agent systems where diverse specialized agents need to work together. It’s the optimal choice for complex software development projects, comprehensive data analysis initiatives, and scenarios requiring varying levels of human involvement in the process.
These three framework is what we use mostly at TokenTek since they cover most use cases, but I would love your feedback about other frameworks such as CrewAI, Semantic Kernel, LlamaIndex, Agno and Atomic Agents. Which framework is your favorite and why did you pick it instead of the three I listed above?
Read more:
Cohere Launches Command A: Enterprise-Grade AI Model Requiring Just 2 GPUs
https://cohere.com/blog/command-a

The News:
- Cohere released Command A, a new enterprise AI model that matches or outperforms OpenAI’s GPT-4o and DeepSeek-V3 while requiring only two GPUs (A100 or H100) for deployment compared to competitors that may need up to 32 GPUs.
- The model features a 256,000 token context window (double the industry average), enabling it to process the equivalent of a 600-page book in a single prompt.
- Command A delivers 156 tokens per second, which is 1.75x faster than GPT-4o and 2.4x faster than DeepSeek-V3, with significantly reduced latency.
- It excels in multilingual capabilities, supporting 23 languages including enhanced Arabic dialect recognition, achieving 98.2% accuracy when responding in Arabic to English prompts.
- Command A is specifically optimized for enterprise applications including tool use, agents, retrieval augmented generation (RAG), and is priced at $2.50 per million input tokens and $10.00 per million output tokens.
My take: Now here’s an interesting new model you probably haven’t heard about. It’s 111 billion parameters in size, and can easily run on a setup with dual A100 or H100 cards. And while you can download the full 111b model and run it locally, you can only run it for non-commercial research purposes. If you need it for commercial use you need to contact Cohere’s Sales team. For most companies my recommendation is to use Gemma 3 by Google if you need to run something locally now, or wait a few weeks/months until Llama 4 is released. But if you are doing non-commercial things and have access to a computer with dual A100 or H100 cards, or if you use lots of Arabic texts, this might be just the model for you.
Read more:
- Cohere targets global enterprises with new highly multilingual Command A model requiring only 2 GPUs | VentureBeat
- Pricing | Secure and Scalable Enterprise AI | Cohere
Microsoft Announces Copilot for Gaming, AI Assistant for Xbox Players
https://news.xbox.com/en-us/2025/03/13/new-copilot-for-gaming-save-time-help-get-good
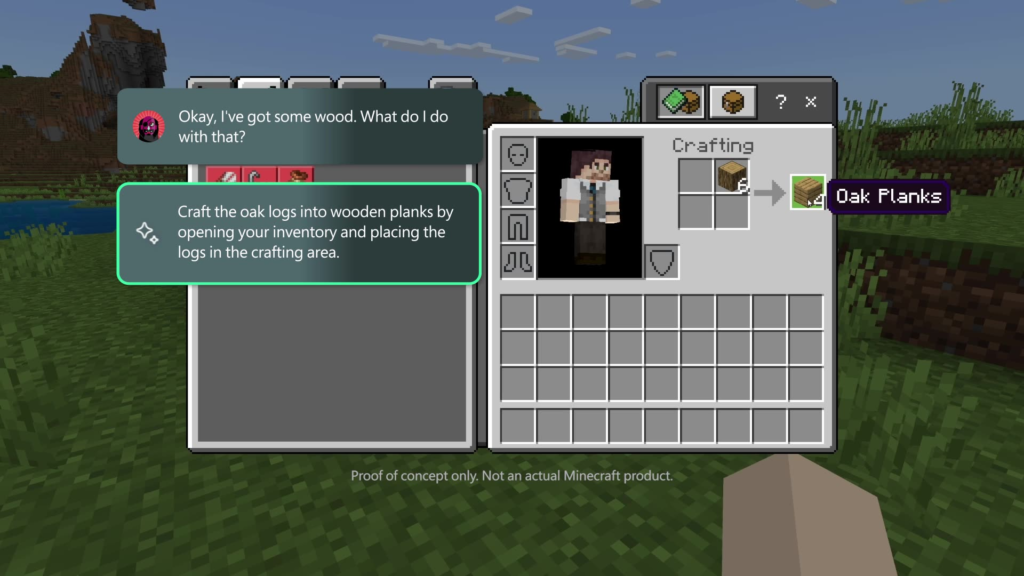
The News:
- Microsoft unveiled Copilot for Gaming, an AI-powered assistant designed to help Xbox players navigate games, offer strategic tips, and streamline their gaming experience.
- The AI companion will provide real-time gameplay assistance by analyzing player actions, suggesting optimal character selections in games like Overwatch 2, and guiding players through mechanics such as Minecraft’s crafting system.
- Copilot for Gaming can help players install games, provide recaps for games they haven’t played in a while, and offer personalized recommendations.
- An initial test version will be available to Xbox Insiders via the Xbox mobile app in April 2025, with plans to expand availability across various devices later.
My take: If you have ever played computer games you know just how immersive it can feel when you really get into them, almost to the point where everything else disappears and it’s just you and the game. And then Microsoft Copilot pops up and asks if you would like suggestions on how to do a side quest that you intentionally skipped an hour ago. Microsoft right now have so many Copilots they are launching: GitHub Copilot, Copilot for Windows, Copilot for Edge, Microsoft 365 Copilot, Microsoft 365 Copilot Chat, Copilot Studio and now Copilot for Gaming. They are really determined to put different copilots in every single user experience they provide, and everything you see on the screen is up for discussion or debate with your Copilot. I’m not so sure this is the right way forward, but as long as they can be disabled (or even better opt-in) then sure, add it to the toaster and fridge while you’re at it.
EuroBERT: A New Family of Multilingual Encoder Models
https://huggingface.co/blog/EuroBERT/release

The News:
- A consortium of 18 European companies, labs, and universities has launched EuroBERT, a family of multilingual encoder models designed for retrieval, classification, and embedding tasks across 15 languages.
- The model family includes three sizes (210M, 610M, and 2.1B parameters), trained on 5 trillion tokens and supporting sequences up to 8,192 tokens.
- EuroBERT delivers state-of-the-art performance specifically for encoder-based tasks like MIRACL, Wikipedia retrieval, XNLI, and PAWS-X classification benchmarks, outperforming existing multilingual encoders like XLM-RoBERTa and mDeBERTa with fewer parameters.
My take: This may be the best name and logotype of all AI models out there, I just love it! EuroBERT is different from generative models like ChatGPT since it focuses exclusively on bidirectional text understanding rather than generation. Unlike generative models that use causal attention masks where tokens can only “see” previous words, EuroBERT employs full bidirectional attention, allowing each word to be contextualized by all surrounding words simultaneously. This architectural difference makes EuroBERT exceptionally powerful for tasks requiring deep semantic understanding, such as information retrieval, document classification, and multilingual search, where it outperforms all existing encoders while using fewer parameters. The model’s specialized design for 15 languages (with emphasis on European languages), support for 8,192-token sequences, and incorporation of modern innovations like grouped query attention and rotary position embeddings addresses a real gap in the AI ecosystem. While generative models have dominated headlines, encoder models remain essential for the foundational understanding tasks that power many practical applications, including the retrieval-augmented generation systems that enhance the capabilities of generative AI itself.