
Last week OpenAI finally launched their successor of GPT-4o: GPT-4.5, and the entire Internet quickly became full of (mostly) disappointed old guys claiming AI-development has stalled. GPT-4.5 does not significantly improve performance in test benchmarks, and since it was initially only available for $200 /month Pro subscribers, very few could actually test it.
I seem to be one of the few people that appreciate what OpenAI did with GPT-4.5. Instead of focusing strongly on a few select artificial benchmarks, they took the strengths of GPT-4o and made it better. GPT-4.5 is more creative, more nuanced, and more knowledgeable than GPT-4o, and hallucinates much less. If you enjoy working with text you will notice it straight away. GPT-4.5 is also a foundation model for future models, and you can bet that the next generation of “thinking” models that are trained with reinforcement learning based on GPT-4.5 will be truly outstanding. So thank you OpenAI for greatly improving ChatGPT at what it’s best at: creative writing, and I believe test-chart reviewers will be more pleased with their next release.
On another note, on March 27 we are finally launching our new AI company TokenTek with a massive party. If you live in Göteborg you are very welcome to sign up here. Our keynote speaker is Andreas Horn, Head of AIOps at IBM. Andreas has over 75 000 followers on LinkedIn and is currently growing at nearly 1 000 new followers per day. We also have Ola Wassvik from Lightbringer talking about how Generative AI is transforming the patent industry, and Kristina Knaving from RISE discussing local vs cloud vs edge models. Seats are limited, so if you’re interested sign up today. Looking forward to meet you! 🥳
Thank you for being a Tech Insights subscriber!
THIS WEEK’S NEWS:
- OpenAI Launches GPT-4.5: Its Most Advanced Conversational AI
- Anthropic Launches Claude 3.7 with Extended Thinking Mode
- Hume AI Launches Octave: First LLM-Powered Text-to-Speech System
- Mercury: Diffusion LLMs Achieve 10x Faster Text Generation
- Andrej Karpathy Releases Practical Guide “How I Use LLMs”
- Sesame Unveils Conversational Speech Model to Cross the “Uncanny Valley” of Voice
- Google Launches Free Gemini Code Assist for Individual Developers
- Hugging Face Launches FastRTC: Python Library for Real-Time AI Communication
- ElevenLabs Launches Scribe: World’s Most Accurate Speech-to-Text Model
- OpenAI Rolls Out Deep Research to All Paying Subscribers
- Andrew Ng Launches Agentic Document Extraction for Advanced PDF Analysis
- Microsoft Launches Phi-4 Models for Multimodal AI on Edge Devices
- IBM Launches Granite 3.2 – Smarter with Reasoning and Vision
OpenAI Launches GPT-4.5: Its Most Advanced Conversational AI
https://openai.com/index/introducing-gpt-4-5
The News:
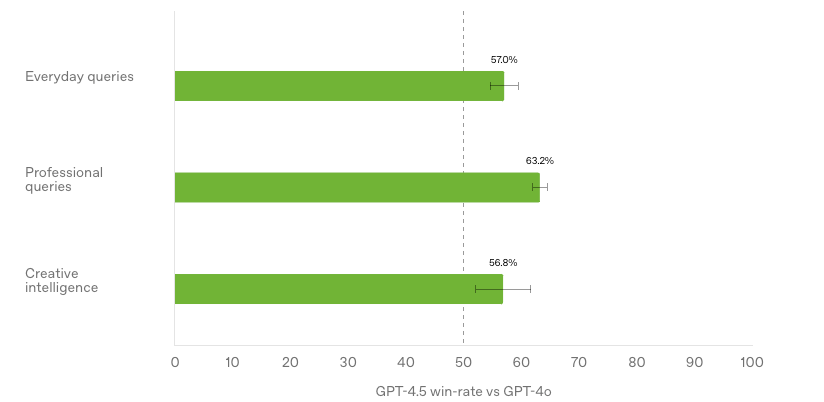
- Last week OpenAI released GPT-4.5, their “largest and best model for chat yet”. The model improves its ability to recognize patterns, draw connections, and generate insights by significantly scaling up pre-training and post-training. Pro users can access it immediately, with a broader rollout to Plus, Team, Enterprise, and Edu users in the coming weeks.
- GPT-4.5 has better “emotional intelligence” (EQ), allowing it to interpret subtle cues, understand user intent more effectively, and respond in a more natural way. This makes it particularly useful for writing, programming, and problem-solving tasks.
- Compared to previous models, GPT-4.5 has a broader knowledge base and a lower hallucination rate, improving factual accuracy and reliability across various topics.
What you might have missed: Andrej Karpathy did an in-depth-review of GPT-4.5’s improvements, focusing on creativity, world knowledge, and emotional intelligence. He concludes that GPT-4.5 is a small but definitely noticeable improvement over GPT-4, thanks to 10x more pre-training compute. It feels better overall – more creative, nuanced, and knowledgeable – but not in ways that are easy to measure. Its reasoning abilities (like math and coding) haven’t advanced much yet, likely because it hasn’t gone through deeper reinforcement learning yet. Instead, it shines in areas like humor, analogy-making, and general understanding.
My take: You have probably also read dozens or hundreds of posts of people looking at different benchmarks and being disappointed that GPT-4.5 does seem to improve a lot on test benchmarks. But the most important benchmark of all is when you use it yourself. How does it “feel” to you as a writing partner. How good is it to understand your intent, so it gives you the right information? And can you trust it to give you the right information and not make things up? In my view GPT-4.5 is exactly what I expected it to be and I am very happy OpenAI stuck with this route instead of trying to make it solve artificially made up benchmarks. I use ChatGPT for most of my creative writing, and from my limited experience with it since its launch last week this update is a keeper, it’s much better on everything when it comes to daily use. I am very happy OpenAI went this route, and it seems to be in direct contrast with xAI who focused a lot on benchmarks but ended up with a model that performs quite poor in everyday use.
Read more:
Anthropic Launches Claude 3.7 with Extended Thinking Mode
https://www.anthropic.com/research/visible-extended-thinking
The News:
- Anthropic launched Claude 3.7 Sonnet, its “most intelligent model to date” and the “first hybrid reasoning model on the market”. The model combines quick responses with extended reasoning capabilities in a single system, allowing users to toggle between standard mode for everyday queries and extended thinking mode for complex problems requiring deeper analysis.
- The model features a drop-down menu that lets users select their preferred thinking mode: Standard Mode for general queries and Extended Mode for tasks requiring in-depth analysis, such as coding and mathematics. In extended thinking mode, Claude takes additional time to analyze problems in detail, plan solutions, and consider multiple perspectives before responding.
- Claude 3.7 Sonnet makes it possible for users to see the model’s step-by-step thinking process. Developers can control how long the model spends on a problem by setting a up a “thinking budget”.
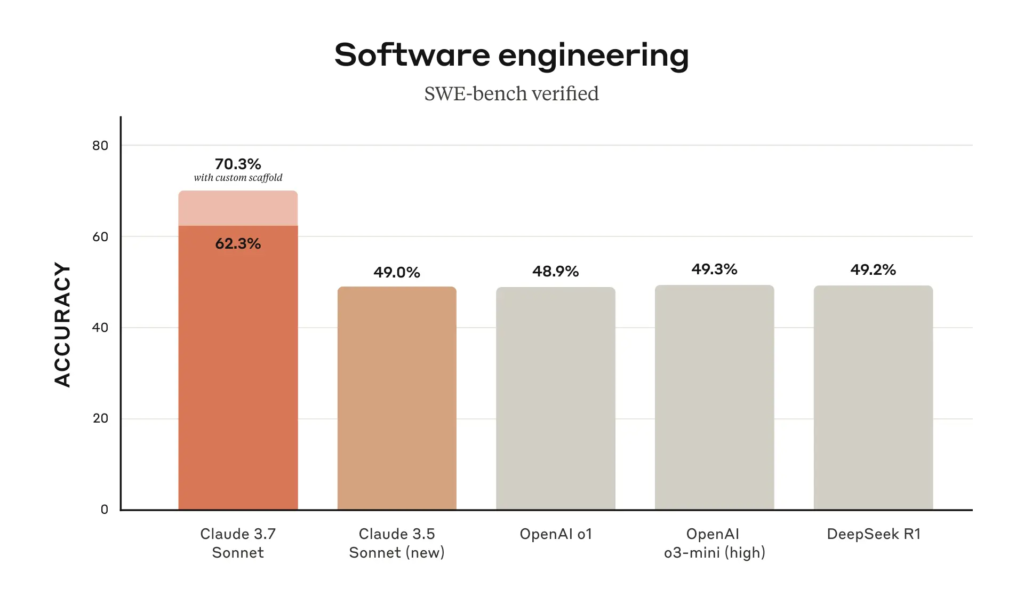
- The new model excels at coding tasks, achieving an industry-leading 70.3% for standard mode on SWE-bench Verified. Anthropic also launched Claude Code, a command-line tool for “agentic coding” that allows developers to assign tasks to the AI directly from a terminal.
My take: I have used Claude almost daily for AI-programming since June 2024, and based on this week’s releases where OpenAI GPT-4.5 is better at conversations but not-so-much-better at coding, it looks like I will continue this way for a few months more. I tried Claude Code over the weekend – the terminal utility where you can ask it to do tasks directly into the code base, but I wasn’t very impressed. It does not come close to using Cursor but it was terribly expensive. According to Anthropic CEO Dario Amodei in a recent interview Claude 4.0 is coming, and should provide a “substantial leap” in performance. Maybe that is when “Claude Code” becomes useful, because right now you still need to be decent at programming to steer Claude in the right direction, and hacking around in the terminal is not the right way to do this, at least not for me.
Amazing Claude 3.7 one-shot prompt examples:
- Claude 3.7 (right) blows o3-mini-high (left) out of the water. One-shot big bang simulation : r/ClaudeAI
- OMG Claude Sonnet 3.7 is insane. I got this stunning 3D city with one shot. r/singularity
Read more:
Hume AI Launches Octave: First LLM-Powered Text-to-Speech System
https://www.hume.ai/blog/octave-the-first-text-to-speech-model-that-understands-what-its-saying
The News:
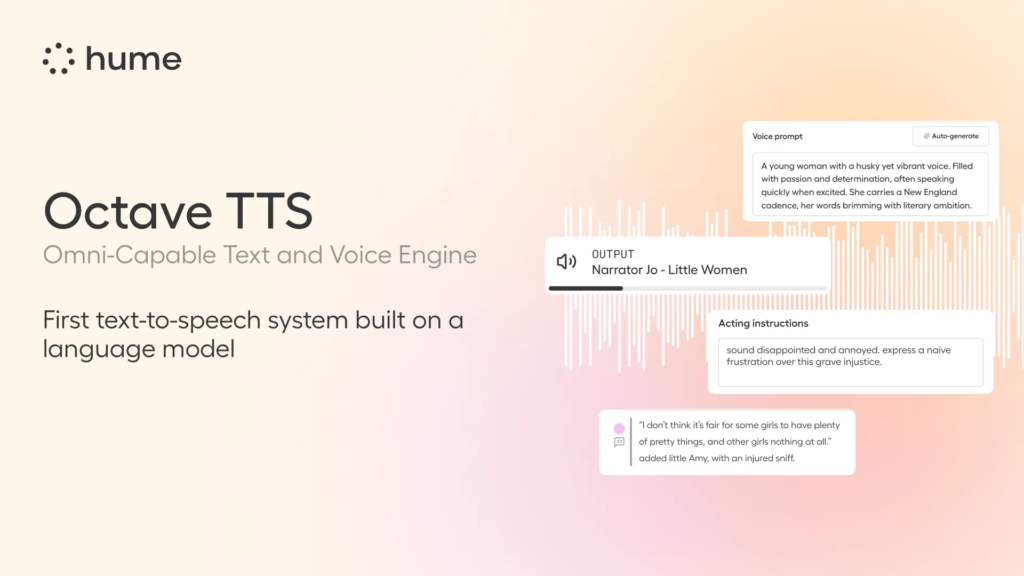
- Hume AI released Octave, the first text-to-speech system powered by a large language model (LLM) that actually understands what it’s saying. Unlike conventional TTS that merely reads words, Octave comprehends context and meaning, allowing it to deliver speech with appropriate emotions, rhythm, and intonation based on the content.
- Users can create custom AI voices through simple prompts, like “sarcastic medieval peasant” or “literature professor”, with the system generating voices that match specific character traits, demographics, or personalities.
- The system accepts natural language instructions to fine-tune emotional delivery, allowing users to direct voices to whisper, sound angry, or express excitement through simple commands like “happier” or “sadder”.
- Octave maintains consistent character voices across long-form content, making it particularly useful for audiobooks, voiceovers, and game development where emotional continuity is important.
My take: What a cool and unexpected release! Where conventional text-to-speech systems process text without comprehension, Octave interprets plot twists, emotional cues, and character traits to transform that understanding into lifelike speech that can maintain consistent personality and emotional expression across long-form content. If you have a minute then go check their launch video, it show’s you where we are heading with podcasts, audio books and interactive content quicker than you thought was possible!
Read more:
Mercury: Diffusion LLMs Achieve 10x Faster Text Generation
https://www.inceptionlabs.ai/news

The News:
- Inception Labs launched Mercury, the first commercial-scale diffusion large language model (dLLM) that generates text using a “coarse-to-fine” approach rather than the traditional token-by-token method, enabling significantly faster text generation while maintaining high quality.
- Mercury Coder, their first publicly available dLLM, achieves speeds of over 1000 tokens per second on NVIDIA H100 GPUs, which is 5-10x faster than speed-optimized autoregressive models like GPT-4o Mini and Claude 3.5 Haiku that max out at around 200 tokens per second.
- In benchmark testing, Mercury Coder tied for second place on Copilot Arena, outperforming speed-optimized models like GPT-4o Mini and Gemini-1.5-Flash, and even larger models like GPT-4o, while being approximately 4 times faster.
- The diffusion approach allows Mercury to refine its outputs and correct mistakes, making it particularly well-suited for reasoning tasks and structured responses. The company states: “Because diffusion models are not restricted to only considering previous output, they are better at reasoning and at structuring their responses”.
- Mercury is available to enterprise clients through both an API and on-premise deployments, with several Fortune 100 companies already signed up as clients.
My take: This approach to LLMs is unlike all other commercial LLMs that generate text sequentially using autoregressive methods. Mercury’s parallel generation approach aims to solve a key bottleneck in AI text generation that enables dramatically lower inference costs and latency without requiring specialized hardware. Several industry experts have commented about Mercury the past week, you can check some of the articles below. It’s still way to early to know if this will make it into the world’s top foundation models, but who knows. Test-time-compute was first announced in August 2024 and just a few months later we got OpenAI o1.
Read more:
- Diffusion Models Enter the Large Language Arena as Inception Labs Unveils Mercury
- What Is a Diffusion LLM and Why Does It Matter? | HackerNoon
- Andrew Ng on X: “This is a cool attempt to explore diffusion models as an alternative to LLMs.” / X
- Andrej Karpathy on X: “This is interesting as a first large diffusion-based LLM.” / X
Andrej Karpathy Releases Practical Guide “How I Use LLMs”

The News:
- Andrej Karpathy, former OpenAI founding member and Tesla AI director, has released a new 2-hour 11-minute YouTube video titled “How I Use LLMs”, offering a comprehensive, example-driven walkthrough of practical Large Language Model applications.
- The video serves as a follow-up to his previous technical content on LLM training, focusing instead on real-world applications and how Karpathy personally uses these AI systems in his daily workflow.
- The presentation covers the entire LLM ecosystem, including basic interactions, model selection considerations, pricing tiers, and when to use different “thinking models”.
- Karpathy demonstrates various tool integrations including Internet search, deep research capabilities, file uploads, Python interpreters, and data analysis features available in modern LLM platforms. The video also explores multimodal features including audio input/output, image processing (both input and generation), video capabilities, and specialized applications like NotebookLM and podcast generation.
- Advanced features covered include ChatGPT’s memory system, custom instructions, and how to create custom GPTs for specific use cases.
My take: Wow, what an amazing video! Seriously, every “heavy AI user” should just book two hours in their calendar, grab a drink and go watch this video. I learnt a lot from it, and I am quite certain you will too. What makes this video unique is that Karpathy is not just “yet another self-proclaimed expert in AI tool use”, he is one of the AI pioneers of AI with a unique insider perspective. This together with his previous video Deep Dive into LLMs like ChatGPT are must-watch videos for everyone in the industry.
Read more:
Sesame Unveils Conversational Speech Model to Cross the “Uncanny Valley” of Voice
https://www.sesame.com/research/crossing_the_uncanny_valley_of_voice#demo
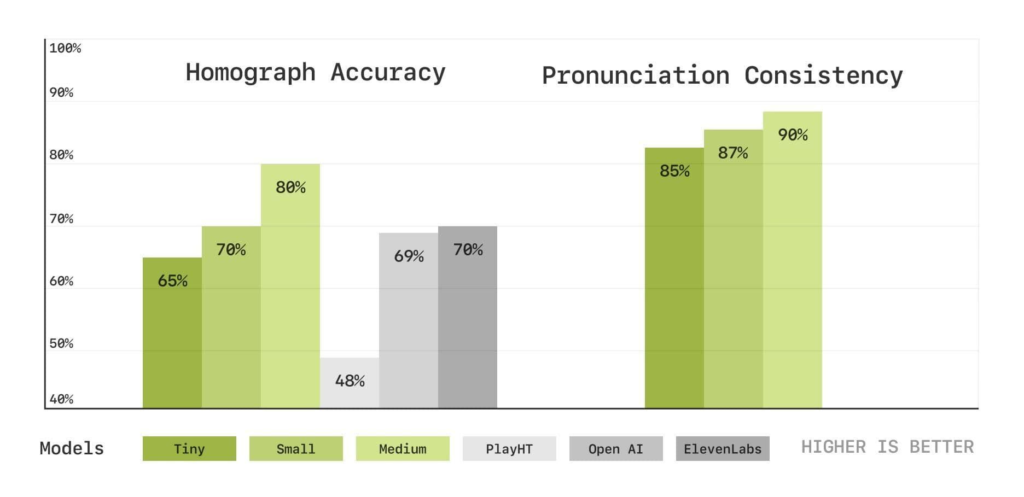
The News:
- Sesame introduced a Conversational Speech Model (CSM) designed to create more natural and contextually aware AI speech. The technology aims to overcome the “emotional flatness” of current voice assistants by incorporating nuanced vocal elements like tone, pitch, rhythm, and emotion to make interactions feel more genuine and human-like.
- The model operates as a single-stage multimodal learning system using transformers, which improves efficiency and expressivity. According to the company, CSM “leverages the history of the conversation to produce more natural and coherent speech”.
- Sesame’s approach focuses on achieving “voice presence” through four key components: emotional intelligence, conversational dynamics, contextual awareness, and consistent personality.
- In subjective testing, when presented without conversational context, human evaluators showed no clear preference between CSM-generated and real human speech. However, when context was included, evaluators still preferred original human recordings.
- Sesame plans to open-source key components of their research under an Apache 2.0 license.
My take: Everyone all over the Internet seems to be raving about this “uncanny valley” model but I.. thought.. it .. sounded .. a .. bit … unnatural. It has lots of small pauses between the words when speaking and the tone often felt wrong. I would love to hear your feedback, does it feel to you like you are talking to another person or does it sound artificial to you too? It’s yet another reminder to not trust the benchmarks, especially when they come from the same company as the one creating the product. You can run the demo on their web page.
Google Launches Free Gemini Code Assist for Individual Developers
https://blog.google/technology/developers/gemini-code-assist-free

The News:
- Google released a free version of Gemini Code Assist, their AI-powered coding tool designed for individual developers including students, freelancers, and hobbyists.
- Powered by Google’s Gemini 2.0, the assistant can produce entire code segments, complete code as you type, and offer general coding support through a chatbot interface.
- The free tier offers 180,000 code completions per month, which Google claims is “90 times more” than “other popular free coding” assistants that cap users at 2,000 completions monthly (they are clearly referring to GitHub Copilot Free here).
- Gemini Code Assist supports all programming languages in the public domain and integrates with popular development environments including Visual Studio Code, GitHub, and JetBrains IDEs. Gemini Code Assist also includes a large context window of up to 128,000 tokens.
My take: How do you get developers that are getting quite comfy with Claude to try another own coding assistant? Releasing it completely free is one way. Gemini Code Assist is still no match for Claude 3.7 when it comes to coding quality, but it’s definitely on par or better than GPT-4o and GitHub Copilot. If you are using the free tier of Copilot today you should definitely check this one out.
Hugging Face Launches FastRTC: Python Library for Real-Time AI Communication
https://huggingface.co/blog/fastrtc

The News:
- Hugging Face released FastRTC, an open-source Python library that simplifies building real-time audio and video AI applications. The library addresses a significant challenge for ML engineers who may lack experience with technologies like WebRTC, making it possible to create sophisticated voice and video applications with just a few lines of code.
- FastRTC features automatic voice detection and turn-taking capabilities built-in, allowing developers to focus on the logic for responding to users rather than managing communication protocols.
- The library includes an automatic WebRTC-enabled Gradio UI for testing or production deployment, making it easy to prototype and deploy applications quickly.
- The library comes with built-in speech-to-text and text-to-speech capabilities, making it straightforward to integrate with LLMs and other AI models.
My take: According to Freddy Boulton, one of FastRTC’s creators, “Building real-time WebRTC and Websocket applications in Python was incredibly difficult – until now”. And yes, I have tried it myself and it was not fun. Python was not what you would pick for those use cases, until now. Amazing work by Hugging Face, and looking forward to see how this will be used in the coming months!
ElevenLabs Launches Scribe: World’s Most Accurate Speech-to-Text Model
https://elevenlabs.io/blog/meet-scribe

The News:
- ElevenLabs released Scribe, their first Automatic Speech Recognition (ASR) model that claims to be the world’s most accurate transcription tool. Scribe outperforms competitors like Google’s Gemini 2.0 Flash, OpenAI’s Whisper V3, and Deepgram Nova-3 in benchmark tests across multiple languages.
- Scribe supports 99 different languages, including traditionally underserved ones like Serbian, Cantonese, and Malayalam, where competing models often exceed 40% word error rates.
- The model features precise word-level timestamps, allowing for accurate subtitle generation and synchronization with audio content.
- Scribe includes advanced speaker diarization, capable of identifying and distinguishing up to 32 different speakers within a single audio file.
- The system automatically tags non-speech audio events such as laughter, sound effects, music, and background noise, providing enhanced context for transcriptions.
- Scribe is currently optimized for batch processing of pre-recorded audio, with ElevenLabs planning to release a low-latency version for real-time applications in the near future.
- Pricing is set at $0.40 per hour of transcribed audio, with a 50% discount offered for the first six weeks after launch.
My take: Wow! Just … wow! I have tried so many different transcription tools, and I often just end up creating subtitles on Youtube and then go in and do manual adjustments. If Scribe properly understands my dialect which is something between Swedish and English (“Swenglish”?) then it’s a no-brainer at $0.40 per hour of material. I will definitely be trying this a lot in the coming weeks!
OpenAI Rolls Out Deep Research to All Paying Subscribers
https://techcrunch.com/2025/02/25/openai-rolls-out-deep-research-to-paying-chatgpt-users/
The News:
- Last week OpenAI expanded access to Deep Research, previously limited to Pro $200 / month users, to all paying ChatGPT subscribers including Plus, Team, and Enterprise tiers.
- Plus, Team, Edu, and Enterprise users will receive 10 Deep Research queries per month as part of their subscription, while Pro users will see their monthly limit increased from 100 to 120 queries.
- Deep Research uses OpenAI’s o3 reasoning model, optimized for web browsing and data analysis, allowing it to autonomously search the internet and synthesize information from hundreds of online sources
My take: I have used OpenAI Deep Research quite a lot and have been getting mixed results. For some queries it’s amazing, for others it fails quite bad. One explanation could be that OpenAI is using Bing for all queries – if you have ever tried “going full Bing” and then went back to Google you know what I mean. I have also used Perplexity Deep Research the past week and compared the results by running OpenAI Deep Research in parallel, and based on these two OpenAI Deep Research is better almost every time, at least for my use cases. So if you need a Deep Research tool, give it a try and try to determine for what queries it works for you.
Andrew Ng Launches Agentic Document Extraction for Advanced PDF Analysis
https://landing.ai/agentic-document-extraction
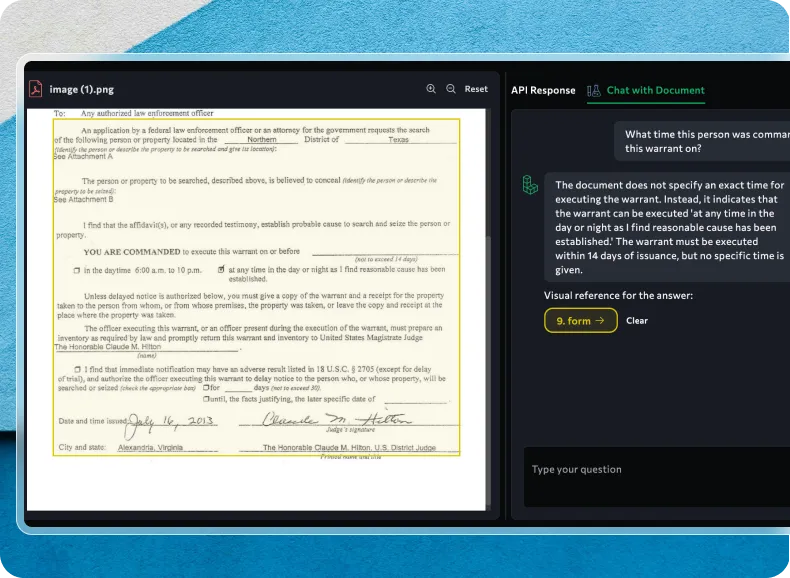
The News:
- Agentic Document Extraction is a new AI-powered approach that promises to promises to revolutionize PDF analysis by going beyond traditional OCR methods to interpret documents based on their visual elements, layouts, and charts, making it particularly valuable for analyzing complex financial documents.
- The technology breaks documents down into individual components and uses reasoning to examine and connect these pieces, taking into account document layout and visual elements rather than just extracting text.
- Key features include capturing complex layouts with checkboxes, extracting data from charts and tables, and providing visual grounding for enhanced accuracy.
What you might have missed: This is a major competitor to the company Pulse, which presents itself as “The world’s best document processing engine”. Pulse was very quickly to test the Agentic Document Extraction framework and got over 50% hallucinated values in complex financial tables, missing negative signs and currency markers and completely fabricated numbers in several instances.
My take: This framework seems to be based on Andrew’s previously released Agentic Object Detection framework, and of course companies threatened by it like Pulse (above) found that it was nearly completely useless in their internal testing. We got our first usable multimodal model less than a year ago (GPT-4o) so I don’t expect these generalized models to perform amazingly well even today. But give it a year or two and there is a risk Pulse will have to reconsider their business offering once these models start to get really good.
Microsoft Launches Phi-4 Models for Multimodal AI on Edge Devices
https://azure.microsoft.com/en-us/blog/empowering-innovation-the-next-generation-of-the-phi-family/

The News:
- Microsoft expanded its Phi family with two new small language models (SLMs) designed for on-device AI applications: Phi-4-multimodal (5.6B parameters) and Phi-4-mini (3.8B parameters).
- The flagship Phi-4-multimodal can process text, images, and audio simultaneously within a single unified architecture, enabling applications to understand and reason across multiple input types at once.
- Phi-4-mini, the text-only version, excels at reasoning, mathematics, coding, and instruction-following tasks despite its compact size, supporting sequences up to 128,000 tokens.
- Both models use architecture optimizations including decoder-only transformers and grouped query attention (GQA) to reduce hardware usage and improve processing speed.
- The models are available under the MIT license, permitting commercial use, and can be accessed through Azure AI Foundry, Hugging Face, and the NVIDIA API Catalog.
My take: Great work by Microsoft here, Phi-4-multimodal even outperforms both Gemini-2.0-Flash and Gemini-1.5-Pro in some benchmarks. I believe these Phi-4 models will be mostly used by Microsoft in specific Windows 11 tasks, since it can run on “Copilot+ PCs” with built-in NPUs. Phi-4 are Microsoft’s “local offloading models” to be used for simpler tasks, avoiding sending everything to the cloud, much like Apple Intelligence uses simpler on-device models for specific tasks. But having them released under the MIT license means any company can use them for any purpose, which is great if you need small multimodal models for a specific purpose.
IBM Launches Granite 3.2 – Smarter with Reasoning and Vision

The News:
- IBM released Granite 3.2, the latest iteration of its enterprise-focused AI model family, featuring new reasoning capabilities, vision processing, and enhanced safety features.
- The flagship Granite 3.2 Instruct models (available in 8B and 2B parameter sizes) now include experimental chain-of-thought reasoning with a “reasoning toggle” that lets developers turn reasoning on or off depending on the task complexity, optimizing compute resources and costs.
- A new 2B-parameter vision language model (VLM) focuses specifically on “document understanding” tasks, rivaling performance of much larger models like Llama 3.2 11B and Pixtral 12B on enterprise benchmarks.
- All Granite 3.2 models are available under the permissive Apache 2.0 license on Hugging Face, with select models also available on IBM watsonx.ai, Ollama, Replicate, and LM Studio.
My take: When should you use these small open-source models instead something bigger, like DeepSeek 70B running on an NVIDIA A100 or H100? There are quite a few use cases, but you must be absolutely certain that the model you pick will be enough for your needs. Personally I would go for a bigger model every day of the week if possible, but if you know that these smaller models do exactly what you need and that they do it reliably, then Granite 3.2 might be just the models you are looking for.