
Wow this was a crazy week! Meta presented their $10,000 AR glasses as a result from spending over $46 billion on the Metaverse since 2019, OpenAI finally rolled out Advanced Voice Mode, and Duolingo introduced numerous AI powered features!
Two weeks ago Youtube announced automatic audio dubbing, and this week Facebook took it one step further introducing both audio dubbing and automated lip syncing for reels. This will change Facebook and Instagram reels forever, and in a few months we will all be watching tons of AI generated content on a daily basis. I’m still not convinced this is a great idea, what do you think?
IN THIS WEEK’S NEWS:
- Duolingo Launches AI-Powered Mini-Games and Video Call Feature
- Meta Demonstrates Orion: Next Generation AR Glasses
- Meta’s New AI Translation Tool will Change Reels Forever
- Meta Launches Llama 3.2 with Vision and Edge Models
- Alibaba Cloud and Nvidia Announce Collaboration for Autonomous Cars
- OpenAI Rolls Out Advanced Voice Mode (Outside EU)
- Google Launches Significant Updates to Gemini 1.5
- NotebookLM Now Accepts Youtube Videos and Audio Files
- Expert Developers Still Beats AI
Duolingo Launches AI-Powered Mini-Games and Video Call Feature

The News:
- Duolingo just announced new features including Adventures mini-games and Video Call to help with language learning:
- Duolingo Adventures is an immersive game-like experience where users can explore different scenarios in the Duolingo universe, such as getting their passport checked or ordering coffee.
- Duolingo Video Call allows Duolingo Max subscribers to have real-time conversations with Lily, a Duolingo character, that adapts to the user’s skill level. The more proficient you become in your target language, the more advanced and challenging Lily’s conversations will be!
My take: At first glance the “AI Video Call” felt like a gimmicky feature, but on second thought I now think it’s great! Having an AI with endless patience, that adapts the conversation not only in speed but also in vocabulary based on your current skill level is an amazing new feature! My kids are using Duolingo daily, and we are very much looking forward to this update!
Meta Demonstrates Orion: Next Generation AR Glasses
https://www.theverge.com/24253908/meta-orion-ar-glasses-demo-mark-zuckerberg-interview

The News:
- Meta just launched Orion, an internal prototype of their “Next Generation AR Glasses”.
- Technically, the system consists of three hardware devices: The glasses themselves, a connected “neural wristband” for finger control and a “wireless compute puck”, which is the equivalent of a smartphone without the screen.
- The wristband uses “electromyography” to interpret neural signals and translate them to input for the glasses, such as pinch to select or swiping up or down with your thumb.
- Orion has a 70 degree Field-of-View, which is much wider than for example Hololens 2 (that only had 52 degrees FoV).
- There are seven different cameras integrated into the glasses to track your environment.
My take: Reality Labs at Meta has spent over $46 billion on the Metaverse since 2019, so you can understand why they need to showcase products like these even if they are VERY far from being an actual product. The current prototype would be so expensive that virtually no-one could afford it even at an ultra-high price point (the device apparently costs over $10,000 to manufacture according to Meta). While some reviewers like The Verge feel that we are getting closer to “real” AR glasses and that they “look like the future”, I definitely do not think so.
Firstly, it’s three devices, not one. While Apple could in theory use products like the Apple Watch as a “neural wristband” and the iPhone as a “wireless compute puck”, Apple could probably do AR glasses similar to these that work well within the Apple ecosystem. Companies like Meta however cannot use the Apple Watch and the iPhone, and have to resort to a much tougher sell where the potential customer needs to wear both an Apple Watch AND a neural wristband, together with an iPhone AND a wireless compute puck. I don’t ever see this happening, so I believe this to be a dead product branch that should have been cancelled years ago by Meta.
Secondly, if you look at the launch video by Meta I’m not sure that the “overlay” approach used is the best approach for Augmented Reality, I think it looks like crap. Every overlaid screen they showed looked dull with poor contrast and you could see straight through it. I think Apple’s approach with Vision Pro for AR is much more sound, where they create a new “reality” based on stereoscopic video cameras and 3D overlays. Similarly to the new AirPods Pro 2 with hear-through, this opens up way more interesting opportunities for processing the real world and adapting it for the end-user. Rendering a new augmented reality allows for overlaid content that is not see-through – which is much better for reading documents and watching videos, and also provides the feeling of “magic” where digital objects look the same as other objects. I just don’t think glasses with a see-through display is the way forward, if there is any way forward for these kind of systems. What do you think?
Read more:
- Exclusive: We tried Meta’s AR glasses with Mark Zuckerberg – YouTube
- Meta Connect 2024: Everything Revealed in 12 Minutes – YouTube
Meta’s New AI Translation Tool will Change Reels Forever
https://about.fb.com/news/2024/09/metas-ai-product-news-connect/

The News:
- Last week Youtube announced automatic audio dubbing to translate clips between English, Spanish, French, Portuguese, Italian and more. This week Meta goes even further, announcing both automatic audio dubbing as well as AI-powered lip syncing.
- The AI translation tool will learn from your voice profile and make sure the generated voice sounds very close to your own voice (“it’s going to be in your authentic voice” according to Zuckerberg).
- The AI Translation tool is currently rolling out to a small group of test users in English and Spanish, but will expand to more languages and creators in the future.
- The new AI translation tool and the new Meta AI voice assistant feature are all based on the new Llama 3.2 model, also launched last week.
My take: The demo (seen below) looks very impressive, and it also showcases the power of the open source model Llama 3.2. It won’t be long now until most content we consume will have some or all parts of it AI-generated, and I am still not sure if that is a good thing. What do you think?
Read more:
- You can see a live demo of the AI translation tool here: Mark Zuckerberg says that Instagram Reels will now start to automate dubbing | TikTok
Meta Launches Llama 3.2 with Vision and Edge Models
https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices

The News:
- Meta just released Llama 3.2, expanding their open-source AI model lineup with new vision capabilities and lightweight edge models:
- New vision models: Llama 3.2 11B and 90B parameter models can now understand and reason about images, with performance close to Claude 3 Haiku and GPT-4o-mini on image recognition and a range of visual understanding tasks..
- Lightweight edge models: Llama 3.2 1B and 3B parameter text-only models are optimized for on-device use, with 128K token context lengths. The 3B model outperforms the Gemma 2 2.6B and Phi 3.5-mini models on tasks such as following instructions, summarization, prompt rewriting, and tool-use, while the 1B is competitive with Gemma.
What you might have missed: While these are truly great open-source models, you are not allowed to use them if you live in the EU. According to the Llama 2.2 use policy, “the Llama 3.2 Community License Agreement are not being granted to you if you are an individual domiciled in, or a company with a principal place of business in, the European Union.”
My take: These are fantastic new models by Meta, released as Open Source for anyone to use. Except those who live in the EU. A large number of companies have now posted an open letter called “Europe needs regulatory certainty on AI” (see below) and it’s worth reading if you live in EU and are wondering why we don’t get all these exciting and free new open source AI models.
Read more: Europe needs regulatory certainty on AI
Alibaba Cloud and Nvidia Announce Collaboration for Autonomous Cars

The News:
- Alibaba’s Large Language Model model Qwen will be integrated into Nvidia’s Drive AGX Orin platform, used by several Chinese electric vehicle manufacturers.
- The partnership aims to enhance in-car voice assistants with better understanding based on visual and environmental data.
- Alibaba and Nvidia are also working on new AI models for Nvidia’s next-generation Drive Thor platform, with advanced driver assistance and autonomous driving.
My take: As car manufacturers continue to remove physical buttons, operating even the simplex of things can now prove to be a very difficult task. For example, in the latest Polestar 3, you now need to press FIVE different buttons on five different screens just to open the glove compartment. Having a good voice assistant that understands what you say and mean is critical with these new simplified interfaces, and with Nvidia integrating Qwen straight into AGX Orin means most Chinese electrical cars will soon become much more capable and easier to use. And hopefully those we design and use in Europe too.
Read more:
OpenAI Rolls Out Advanced Voice Mode (Outside EU)
https://twitter.com/openai/status/1838642444365369814
The News:
- OpenAI has finally rolled out Advanced Voice Mode (AVM) to all ChatGPT Plus and Teams subscribers, featuring new voices and improved functionality compared to the early preview version.
- AVM supports customs instructions and Memory, allowing for personalized instructions.
- AVM is however not available in the EU, the UK, Switzerland, Iceland, Norway, and Liechtenstein.
My take: I believe Advanced Voice Mode has the potential to change how we interact with not only our phones, but technology in general. As I wrote above with the Polestar 3 requiring five button presses on five different screens just to open the glove compartment, there are so many areas in our lives where speech makes perfect sense compared to pressing buttons or interacting on a screen, and the better the voice agents become the easier our every day life will become.
Google Launches Significant Updates to Gemini 1.5
https://twitter.com/rowancheung/status/1838611170061918575

The News:
- Google kept the same names and versions for Gemini 1.5 Pro, but added the suffix “002”. So “Gemini 1.5 Pro 002” and “Gemini 1.5 Flash 002” are the new names for the new models.
- The new “002” versions now produce output up to 2x faster with 3x lower latency compared to previous versions.
- Gemini 1.5 Pro 002 pricing has also been reduced by 50%, and rate limits have been increased significantly (2x higher rate limits on 1.5 Flash and ~3x higher on 1.5 Pro).
- Gemini 1.5 Pro 002 beats OpenAI o1-preview on MATH benchmark, but still doesn’t beat the full, upcoming version of o1 (94.8).
My take: Google is definitely catching up, however these names are among the worst I have seen so far. We are just at the cusp of the next generation LLMs to be launched, so expect even more price cuts in the coming weeks on current models just before the next models such as Gemini 2, Claude 3.5 Opus, GPT-5, Grok 3 and Llama 4 are launched.
NotebookLM Now Accepts Youtube Videos and Audio Files
https://blog.google/technology/ai/notebooklm-audio-video-sources
The News:
- Google NotebookLM is a personalized “AI research assistant” powered by Google Gemini 1.5 Pro.
- Last week Google introduced the feature to add YouTube URLs and audio files to notebooks, meaning you can now use NotebookLM for:
- Analyzing videos and lectures: When you upload YouTube videos to NotebookLM it now summarizes key concepts and allows for “in-depth exploration through inline citations linked directly to the video’s transcript”. Basically it shows you topics discussed in the video which you can click on to view the transcript exactly where the topic was mentioned.
- Finding topics in large audio recordings: NotebookLM will automatically transcribe and index large audio recordings so you can find topics just by asking for them.
My take: My experience with NotebookLM has been very positive so far, and being able to upload large audio files for automatic transcription, and then being able to get key concepts and ask questions about the contents is great. I find it fascinating to see all these new tools and platforms evolve so quickly in parallel with AI models improving at lightning speed, and things will only speed up from here.
Read more:
Expert Developers Still Beats AI
https://codesignal.com/blog/engineering/ai-coding-benchmark-with-human-comparison
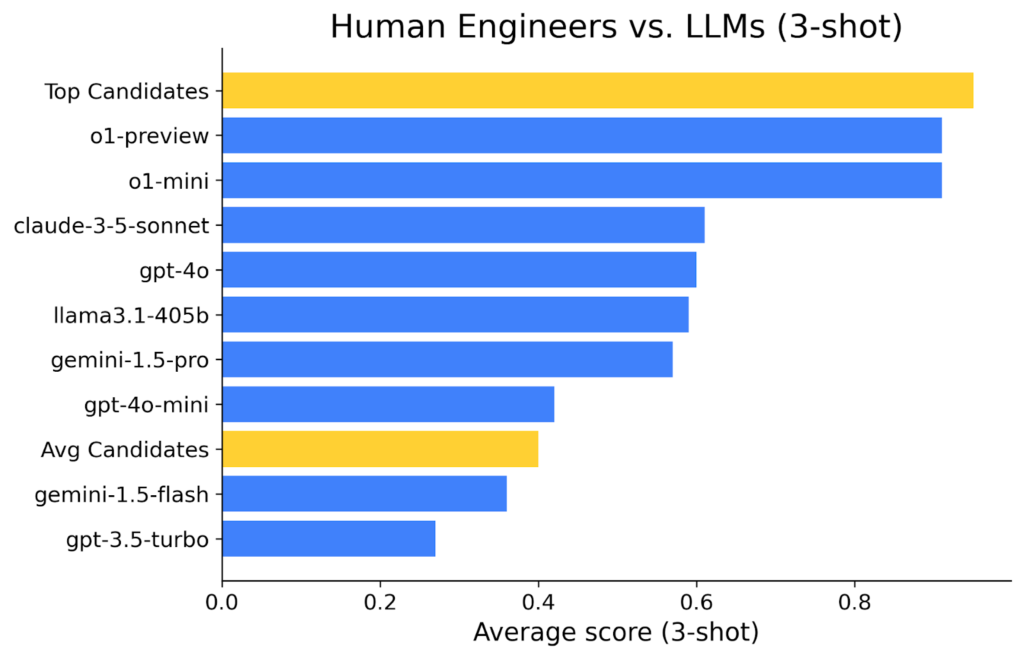
The News:
- Using the same technical assessments used by hundreds of companies, Team Codesignal benchmarked current top AI models against expert and average developers.
- Expert developers are still better than the best AI model (o1), but not by much.
- The improvements introduced with test-time-compute (chain of thoughts) in o1-preview and o1-mini are enormous in terms of problem-solving capabilities.
My take: I expect the final version of o1 to be the first model that now beats expert developers, and the difference between expert developers and AI models will only grow from there. It’s no longer a question of if language models will surpass human programmers, but rather how much better they will be compared to the top developers as each year passes.