
Last week OpenAI launched five new models: GPT-4.1 (including mini and nano variants), o3 and o4-mini, together with a new command-line tool called Codex CLI. You now have six models to choose from in ChatGPT: GPT-4o, GPT-4o with scheduled tasks, GPT-4.5, o3, o4-mini, and o4-mini-high. If you use the API you can add GPT-4.1, GPT-4.1-mini and GPT-4.1-nano to that list. So which one should you use? In my own experience and based on what I have read on multiple forums, GPT-4o is still the best model for everyday productivity. Ask it about documents, work with texts, get feedback, and use the memory function. It’s quick and very good at most tasks. If you have difficult questions and want the agent to act autonomously – analyze images or documents, collect data over the Internet, write Python code for analysis, or even write Python code to create full Powerpoint documents, use o3. It’s amazingly good at complex tasks! Just note that you only have 50 requests per week on a Plus account. GPT-4.5 should probably never have been released, it’s slow and not fine-tuned well and will soon be removed and retired. Once your o3 requests are up then use o4-mini for the rest of the week (you get 50 messages per day for o4-mini-high and 150 messages per day for o4-mini). And if you use the API for coding you should definitely be using a combination of o3 for difficult tasks and GPT-4.1 for everyday coding requests.
To summarize, if you use ChatGPT on the web, use them in the following order:
- GPT-4o – your daily driver
- o3 – for autonomous tasks, image and document analysis, web analysis, super advanced, 50 requests / week
- o4-mini-high – when your o3 requests run out or you don’t want to wait, 50 requests / day
- o4-mini – if you need quicker responses or have run out of o4-mini-high requests, 150 requests / day
- GPT-4o with scheduled tasks – only if you need tasks
- GPT-4.5 – don’t use, will be replaced by GPT-4.1
If you use ChatGPT in the API for programming:
- GPT-4.1 – your daily driver with a huge 1 million context window
- o3 – for difficult tasks, problem solving and refactoring
- o4-mini-high – try it as backup if none of the above works
Among other news this week: JetBrains finally launched their Junie AI agent for their IDEs, so if you love PyCharm and Rider you now have something that at least resembles Cursor or GitHub Copilot in functionality. Microsoft announced Computer Use support for Copilot Studio, and Wikipedia launched a huge structured dataset for AI Training to combat scraper bots. Finally, if you have the need for custom classifiers for tasks like spam detection, moderation, intent recognition, and sentiment analysis, Mistral just launched their Classifier Factory that makes the process so much easier.
Thank you for being a Tech Insights subscriber!
THIS WEEK’S NEWS:
- OpenAI Releases New Reasoning Models: o3 and o4-mini
- OpenAI’s o3/o4 Models Show Significant Progress Toward Automating AI Research Engineering
- OpenAI Launches GPT-4.1 for Developers
- OpenAI Launches Codex CLI: Open-Source Terminal-Based Coding Agent
- JetBrains Launches Junie AI Coding Agent and Updates AI Assistant with Free Tier
- Microsoft Introduces “Computer Use” in Copilot Studio for UI Automation
- Google Rolls Out Gemini 2.5 Flash Preview with Hybrid Reasoning Capabilities
- Wikipedia Releases Structured Dataset for AI Training to Combat Scraper Bots
- Kling AI 2.0 Launches with Advanced Video Generation and Editing Capabilities
- Mistral AI Launches Classifier Factory for Custom AI Classifiers
- Meta to Train AI Models on EU Users’ Public Content
- Claude Adds Research Feature and Google Workspace Integration
OpenAI Releases New Reasoning Models: o3 and o4-mini
https://openai.com/index/introducing-o3-and-o4-mini
The News:
- OpenAI released two new AI reasoning models, o3 and o4-mini designed to “think before responding”, with enhanced capabilities in coding, math, science, and visual understanding.
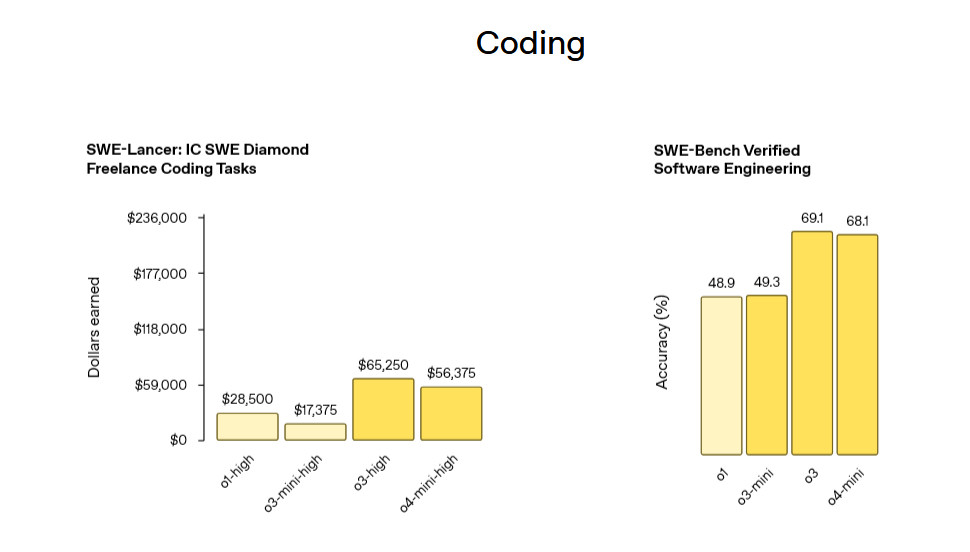
- o3, OpenAI’s most powerful reasoning model to date, sets new performance benchmarks across multiple domains, achieving 87.7% on the GPQA Diamond benchmark for expert-level science questions and scoring 71.7% on SWE-bench Verified for software engineering tasks.
- o4-mini offers comparable performance to o3 at approximately one-tenth the cost ($1.10 vs $10.00 per million input tokens), excelling particularly in math benchmarks where it outperforms o3 on AIME 2024 (93.4% vs 91.6%) and AIME 2025 (92.7% vs 88.9%).
- Both models are now available to ChatGPT Plus, Team, and Pro subscribers, with Enterprise and Edu customers gaining access next week; free users can access o4-mini by selecting the “Think” option.
- OpenAI CEO Sam Altman announced plans to release “o3-pro for the pro tier in a few weeks”, suggesting a continued expansion of the model lineup.
What you might have missed (1): One major feature of o3 and o4-mini is that they can reason with images in their chain of thought. This means that instead of just trying to “translate” an image into a meta description and then switch over to text-based reasoning internally, o3 and o4-mini are able to reason about details in the image, searching for information online related to specific parts before answering in full. This is a complete game changer for complex image and document understanding, and also means the model is outstandingly good at geoguessing.
What you might have missed (2): For both o3 and o4-mini, OpenAI introduced Flex processing, which means that if you are OK with longer response times you will pay a significantly cheaper per-token price. I like this approach much better than the “thinking budget” approach that Google went with for Gemini 2.5 Flash (see below).
What you might have missed (3): OpenAI o3 scored 136 (116 in offline mode) on the Mensa Norway IQ test, the highest score ever recorded by an AI.
My take: These are the first model released by OpenAI that can function as agents, independently executing tasks by determining when and how to use the appropriate tools. They can browse the web, code in Python, do visual analysis and create images. User reports on forums and Reddit have been mixed, where some users report amazing performance and while others say they get worse results than GPT 3.5. It seems these models are very good at problem solving specific tasks, but not so good at creating high volumes of quality source code. For programming I’d recommend you stick with with GPT-4.1 or Claude 3.7 and maybe use these models for specific things like refactoring or solving difficult problems in your code base, preferably in combination with the new Codex CLI tool (see below). If you are developing AI agents these models should be on the top of your list.
Read more:
OpenAI’s o3/o4 Models Show Significant Progress Toward Automating AI Research Engineering
The News:
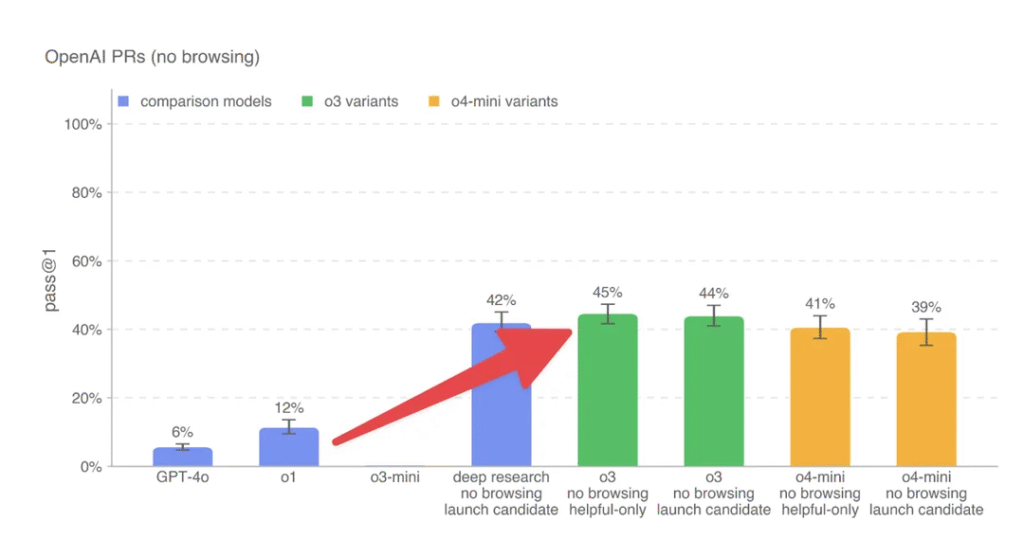
- OpenAI’s new o3 and o4-mini models demonstrate substantial progress in automating the work of AI research engineers, with o3 achieving a 44% success rate on internal pull request tasks and o4-mini scoring 39% on the same benchmark.
- The evaluation process involves setting up agents in a coding environment with a pre-PR branch, providing them with modification instructions, and having them update files using command-line tools and Python, with success measured by passing concealed unit tests.
- Both models show improved capabilities in following instructions and tool usage compared to previous versions, with o3 being OpenAI’s most powerful reasoning model excelling in coding, math, science, and visual perception tasks.
- o3 sets new state-of-the-art benchmarks on Codeforces, SWE-bench (69.1%), and MMMU (82.9%), while o4-mini achieves remarkable performance for its size, particularly in math (93.4% on AIME 2024) and coding tasks.
- o4-mini offers comparable performance to o3 at approximately one-ninth the cost ($1.10 vs $10.00 per million input tokens), making it ideal for high-volume, high-throughput applications.
My take: We are very quickly approaching a future where AI systems can contribute meaningfully to their own development. The 44% success rate on internal pull requests for o3 shows these models are approaching the capability to handle real engineering tasks, not just test cases. Today’s models are still way too inconsistent to just let loose autonomously on a code base, but with increased context windows and higher success rates on internal pull request tasks we are quickly reaching a future where AI models will help significantly in creating future AI models.
Read more:
OpenAI Launches GPT-4.1 for Developers
https://openai.com/index/gpt-4-1
The News:
- OpenAI released a new family of API-only models: GPT-4.1, GPT-4.1 mini, and GPT-4.1 nano, featuring major improvements in coding capabilities, instruction following, and context handling compared to previous versions.
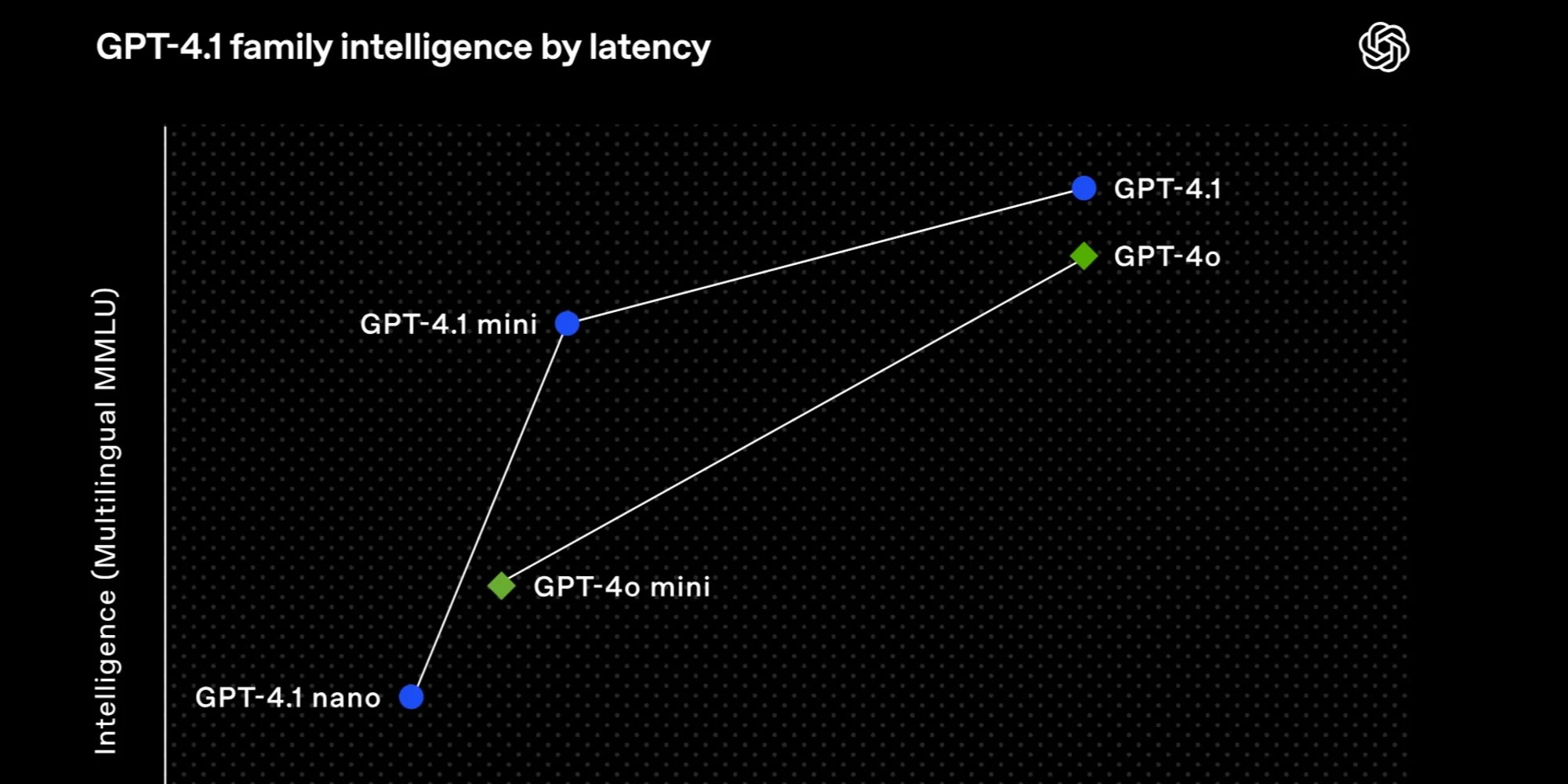
- All three models support an expanded 1 million token context window (up from 128,000 in GPT-4o), allowing them to process massive amounts of information equivalent to more than 8 copies of the entire React codebase in a single interaction.
- GPT-4.1 scores 54.6% on SWE-bench Verified (a 21.4% absolute improvement over GPT-4o), 38.3% on Scale’s MultiChallenge for instruction following (10.5% better than GPT-4o), and achieves state-of-the-art 72.0% on Video-MME for long context understanding.
- The models offer tiered performance and pricing: GPT-4.1 ($2/$8 per million input/output tokens), GPT-4.1 mini ($0.40/$1.60), and GPT-4.1 nano ($0.10/$0.40), with the nano version being OpenAI’s fastest and cheapest model ever.
- OpenAI plans to retire GPT-4.5 by mid-July as GPT-4.1 delivers similar or better results at lower cost and latency.
My take: This is the first time OpenAI has released models with a 1 million context window, which is extremely useful in agentic settings. Performance-wise GPT 4.1 is behind o3, o4-mini, Gemini 2.5 Pro and Claude 3.7 on tests such as SWE-bench Verified. Compared to o3 and o4-mini mentioned above that excel at problem solving, the GPT-4.1 series is primarily targeted for controlled programming, i.e. generating large amounts of high quality software code. Preliminary user feedback has been good, with most people saying it’s on par with Claude 3.7 and in some cases even better for coding.
Read more:
- OpenAI’s new GPT-4.1 AI models focus on coding | TechCrunch
- OpenAI Quietly Launched GPT‑4.1 – A GPT-4o Successor That’s Crushing Benchmarks | Fello AI
OpenAI Launches Codex CLI: Open-Source Terminal-Based Coding Agent
https://help.openai.com/en/articles/11096431-openai-codex-cli-getting-started
The News:
- OpenAI has released Codex CLI, an open-source terminal-based AI coding assistant that brings ChatGPT-level reasoning plus the ability to run code, manipulate files, and iterate on projects under version control.
- The tool allows developers to write, edit, and execute code using natural language commands, with capabilities to move files, alter configurations, and run scripts with full local access.
- Codex CLI offers three configurable approval modes: Suggest (default), which reads files but requires approval for changes; Auto-Edit, which can modify files automatically; and Full-Auto, which can execute commands with minimal supervision.
- It supports multimodal inputs, allowing developers to pass screenshots or sketches to the model for visual context while maintaining access to local code.
My take: OpenAI Codex CLI is very similar to Claude Code, released in February, but with multimodal inputs. Both tools run in the terminal and are mainly used for specific tasks like creating new projects or trying to solve difficult issues in a large code base. I still mostly use Cursor and Claude 3.7 for my daily tasks, but sometimes switch to Claude Code for tasks that require the better context understanding. From what I have read about Codex CLI it works very similar to Claude Code, and with OpenAI in discussions about buying Windsurf they will probably go the same route there – Codex CLI for specific tasks that require huge contexts and Windsurf for your day to day coding.
Read more:
JetBrains Launches Junie AI Coding Agent and Updates AI Assistant with Free Tier
https://www.jetbrains.com/junie

The News:
- JetBrains has officially released Junie, an AI coding agent that works as a virtual collaborator within the IDE, helping developers automate routine tasks and solve complex coding problems that would otherwise require hours of work.
- Junie can perform complex tasks like developing new features, fixing bugs, adding documentation, and writing tests while offering finer control for a human-in-the-loop approach.
- According to SWEBench Verified benchmark of 500 common developer tasks, Junie solves 53.6% on a single run, very close to GPT-4.1 (54.6%).
- JetBrains has also updated its AI Assistant (not Junie) with support for newer models including Claude 3.7 Sonnet, Google Gemini 2.5 Pro, and the latest OpenAI models, plus improved local model integration.
My take: If you enjoy working in the JetBrains environments (like PyCharm or Rider) you probably have been glancing at GitHub Copilot or Cursor for their AI features. Julie is very similar to these tools, and is using Claude as the backend. Junie does not however seem to have specialized small models integrated in the environment for diffs and multiline autocomplete like Cursor, and several users on forums have complained about the performance of Junie. As a result the release seems pretty underwhelming. There is no mention about how many fast requests you have per month, so I am guessing it only uses slow requests (which seem to be the case when looking at early user feedback and the price of just $100 per year). Junie does not seem to support something like .cursorrules and .cursorignore, which are critical to make AI agents do exactly what you want. Still it’s better than nothing, so if you’re a JetBrains user then go ahead and give it a go. Just remember to be strict in your prompting and always review the code before merging. If you have used both Cursor and Junie please give me a DM and let me know your experiences.
Read more:
- Junie is slow… but absolutely great! Cursor killer? : r/Jetbrains
- Coding AI Agent by Jetbrains – Junie – YouTube
Microsoft Introduces “Computer Use” in Copilot Studio for UI Automation
The News:
- Microsoft has launched “computer use” in Copilot Studio as an early access research preview, allowing AI agents to interact with any application that has a graphical user interface across desktop and web environments.
- The new capability enables Copilot Studio agents to click buttons, select menus, and type into fields on screens, automating tasks even when APIs aren’t available for direct system connection. Computer use automatically adapts to changes in apps and websites, using built-in reasoning to fix issues in real time.
- The feature works across multiple browsers including Edge, Chrome, and Firefox, and runs on Microsoft-hosted infrastructure. Users can describe tasks in natural language and watch real-time automation with reasoning traces and UI preview, requiring no coding experience to create these automations
My take: Computer Use sounds cool in theory until you try it out for real. Computer Use does behave better than the LLM on which it is based, and right now we have no LLMs that are good enough for the high-precision and high-performance computer use that Copilot Studio promises. I am guessing Microsoft uses GPT-4o or 4.1 to drive this feature (they haven’t said anything about this), and based on that I can guess how well it will work (i.e. not good at all). The feature is not publicly available, it’s only available to select testers that apply for early access. So take this news with a grain of salt, and let’s see how it performs next month when Microsoft will demo it at Microsoft Build 2025 on May 19.
Read more:
- How Computer-Using Agents Are Transforming Automation in Copilot Studio | Digital Bricks
- Microsoft lets Copilot Studio use a computer on its own | The Verge
Google Rolls Out Gemini 2.5 Flash Preview with Hybrid Reasoning Capabilities
https://developers.googleblog.com/en/start-building-with-gemini-25-flash
The News:
- Google has released an early version of Gemini 2.5 Flash in preview through the Gemini API via Google AI Studio and Vertex AI.
- The model features a unique “thinking budget” parameter that allows developers to control how much reasoning occurs based on prompt complexity, with options ranging from 0 to 24,576 tokens.
- Gemini 2.5 Flash maintains the same input capabilities as previous versions (text, images, video, audio and 1 million context window) but increases maximum output length to 64K tokens, up from 8K in version 2.0.
- The model automatically adjusts reasoning levels based on task complexity, using minimal reasoning for simple queries like translations and higher reasoning for complex math problems.
My take: This is a new take for models where you now have a hybrid reasoning model that can be precisely controlled. Have a simple task? Set the thinking budget to zero to disable reasoning completely. Or set it to an arbitrary value to increase thinking capacity. While I understand how Google reasoned about this, I am not really sure this is the right way forward. I can see how it might work if you have an LLM that performs the same task over and over. But that is rarely the case in agentic environments. Sometimes it might need to think harder, and if your budget is cutoff then the agent won’t be able to. So the only times this option is really usable is when you have an agent perform very similar tasks with the same documents expecting it to solve issues in the exact same way. Some users have proposed that you could use a pre-processing step where another model would be trained to decide how much reasoning budget a specific question requires. I don’t think this is a good design decision and would rather have the LLM API decide the budget based on difficulty.
Read more:
- Google’s Gemini 2.5 Flash introduces ‘thinking budgets’ that cut AI costs by 600% when turned down | VentureBeat
- “Thinking Budget” is the real revelation of Gemini Flash 2.5 – with intent for high volume production tasks : r/Bard
Wikipedia Releases Structured Dataset for AI Training to Combat Scraper Bots
https://enterprise.wikimedia.com/blog/kaggle-dataset

The News:
- Wikimedia Enterprise has launched a beta dataset on Kaggle providing structured Wikipedia content in English and French specifically designed for machine learning workflows.
- The dataset offers pre-parsed article data in JSON format, including abstracts, short descriptions, infobox data, image links, and segmented article sections, eliminating the need for developers to scrape Wikipedia directly.
- All content is freely licensed under Creative Commons Attribution-Share-Alike 4.0 and GNU Free Documentation License, making it immediately usable for modeling, benchmarking, alignment, fine-tuning, and exploratory analysis.
- The release comes as Wikimedia Foundation reported a 50% increase in bandwidth usage since January 2024, with 65% of resource-consuming traffic coming from bots scraping content for AI training.
My take: If you need high quality content for model training and have considered to go scraping Wikipedia, then now hopefully this dataset will do the job for you. The dataset itself is around 113GB in size, available in English and French, and is based on the Wikimedia Enterprise html snapshots. Let’s hope this helps to reduce the agent traffic to Wikipedia, and kudos to Kaggle for hosting it!
Read more:
Kling AI 2.0 Launches with Advanced Video Generation and Editing Capabilities
https://app.klingai.com/global/release-notes

The News:
- Kuaishou Technology has released Kling AI 2.0, featuring upgraded KLING 2.0 Master for video generation and KOLORS 2.0 for image generation, designed to give creators more precise control over their AI-generated visual content.
- The new Multi-modal Visual Language (MVL) framework allows users to communicate complex creative concepts through combined image references and video clips, enabling more accurate expression of identity, style, action sequences, and camera movements.
- KLING 2.0 Master shows significant improvements in prompt adherence, motion quality, and visual aesthetics, with internal evaluations showing a win-loss ratio of 182% against Google Veo2 and 178% against Runway Gen-4.
- The Multi-Elements Editor for KLING 1.6 enables users to add, swap, or delete elements in existing videos using simple text or image inputs, effectively providing video inpainting capabilities.
- KOLORS 2.0 now supports over 60 different artistic styles and includes new image editing features such as partial redrawing, expansion, inpainting, and outpainting.
My take: Just when you thought text-to-video generation was getting ridiculously good with Google Veo2 and Runway Gen-4, Kling 2.0 is released showing a win-loss ratio of 182% against Google Veo2 and 178% against Runway Gen-4. The platform now ranks first in the Image to Video category with an Arena ELO benchmark score of 1,000, surpassing competitors like Google Veo 2 and Pika Art. The new Multi-modal Visual Language (MVL) framework is pretty cool, and if you have a few minutes I’d recommend you check out their web page for details. Early user feedback from forums have been really good, with the main negative being the price of around $2 for a 10 second clip, with many saying it’s unaffordable for casual users. Kling however already has over 22 million users, with over 15,000 developers integrating their API in various apps.
Read more:
- Kling AI Advances to the 2.0 Era, Empowering Everyone to
- Kling AI 2.0: Everything You Need to Know! – The AI Tribune
Mistral AI Launches Classifier Factory for Custom AI Classifiers
https://docs.mistral.ai/capabilities/finetuning/classifier_factory

The News:
- Mistral AI has released Classifier Factory, a new tool to build and deploy custom classifiers for tasks like spam detection, moderation, intent recognition, and sentiment analysis.
- The tool is based around Mistral’s small models and include comprehensive documentation and cookbooks for specific applications such as intent classification, moderation, and product classification.
My take: Without Classifier Factory, creating a custom classifier is a complex, technical process requiring extensive expertise. You’d need to collect and preprocess large amounts of data, handle missing values and outliers, transform data into numerical format, select relevant features, choose an appropriate model architecture, tune numerous hyperparameters, train the model (which could take days), evaluate performance, deploy the model on your own infrastructure, and continuously maintain it as data patterns evolve. With Mistral’s Classifier Factory, the process is much simplified: you prepare your data in a standardized JSON Lines format (with examples of text and corresponding labels), upload it to Mistral’s platform, select the pre-optimized ministral-3b model, adjust just two hyperparameters (training steps and learning rate), and let Mistral handle the training and deployment automatically. Definitely check this one out if you are training your own classifiers today!
Meta to Train AI Models on EU Users’ Public Content
https://about.fb.com/news/2025/04/making-ai-work-harder-for-europeans/
The News:
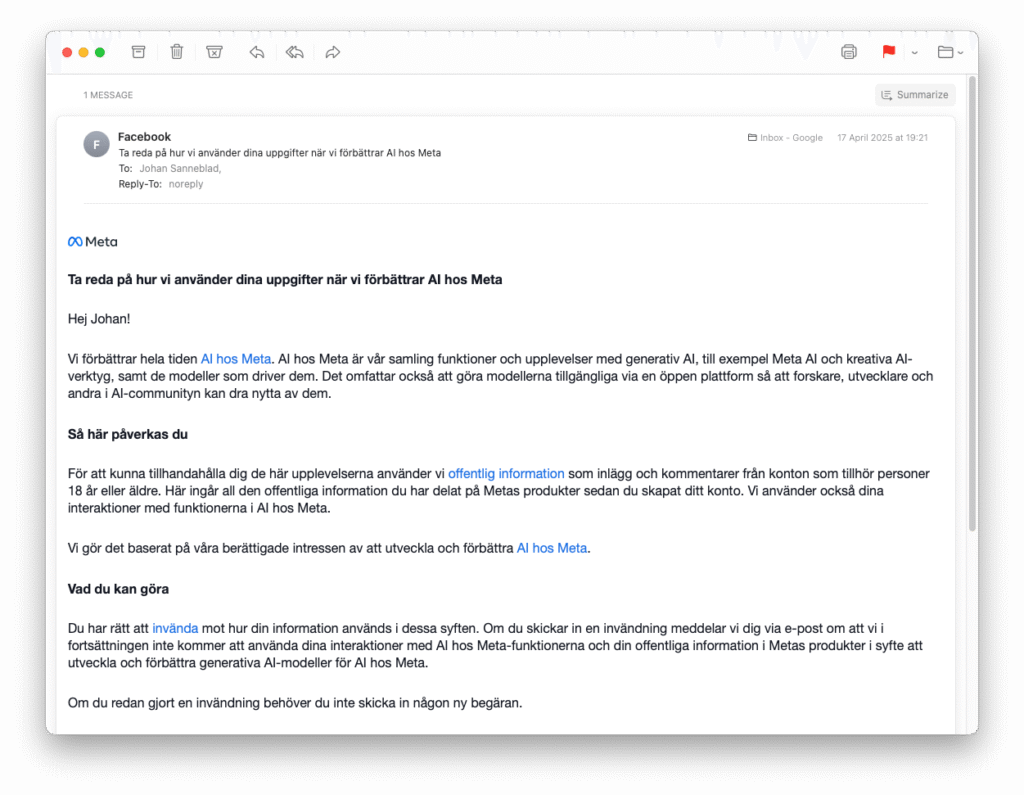
- Meta just announced plans to train its AI models using public content shared by adults on its platforms in the European Union, including public posts, comments, and interactions with Meta AI.
- Starting last week, EU users will receive in-app and email notifications explaining the data usage with a link to an opt-out form, allowing them to object to their data being used for AI training (see photo above).
- The company will not use private messages with friends and family or public data from users under 18 for training purposes.
- This move follows the successful launch of Meta AI in Europe last month and comes after receiving approval from the European Data Protection Board in December 2024.
- Meta states this training is essential for its AI to understand European “dialects and colloquialisms, hyper-local knowledge and distinct ways different countries use humor and sarcasm”.
My take: I really do not like these opt-out mechanisms for AI training and would much rather prefer opt-in, but I guess no-one would do that. If you are a Facebook or Instagram user you got a similar email to the one above last week, and I’m very curious if you even noticed that this was the email you should have interacted with to opt out of AI training from all your publicly available comments or posts. Did you catch it, and did you interact with it? Did you opt out? I’m curious, please leave a comment!
Claude Adds Research Feature and Google Workspace Integration
https://www.anthropic.com/news/research

The News:
- Anthropic has launched a new Research feature for Claude AI that enables autonomous multi-step investigations across both web content and internal work documents.
- The Research feature works “agentically”, independently determining what information to gather next while providing verifiable citations in responses that take just minutes to generate
- Claude also now integrates with Gmail and Google Calendar, expanding its previous Google Docs integration to provide a more comprehensive view of users’ work context without manual file uploads.
- Google Workspace integration allows Claude to compile meeting notes, identify action items from email threads and search relevant documents, with inline citations for source verification.
My take: Claude Research is like Deep Research in ChatGPT but with one important addition: [It can also search your internal work context]( Claude can search across both your internal work context and the web to help you make decisions and take action faster than before.)! Ask it to go through your latest meeting notes and add links to external services that might be relevant to the discussion, or to go through your latest market plan and evaluate it based on the most recent research. If you have ever copy/pasted information to ChatGPT Deep Research you know how much easier it would be if the LLM automatically could access the right documents (it actually builds up a vector database of your entire Google Drive). I can see why most organizations would not want to enable this, but for those daring enough to go for it there is a huge productivity potential here. Preliminary user feedback shows it works great for:
- Marketing teams preparing product launches
- Sales teams preparing for client meetings
- Engineers analyzing technical documentation
- Students creating personalized study plans
- And much more…
Read more: