
Last week Meta launched their new Llama 4 models that scored amazingly well on benchmarks. Yann LeCun, Chief AI Scientist at Meta, wrote “BOOM! The Llama-4 brood is out”, and Ahmad Al-Dahle, Head of GenAI at Meta, wrote “Llama 4 Behemoth outperforms GPT4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro”. Boom indeed, because when users got access to the models they performed among the worst of all recent models. In my newsletter last week I wrote “Maybe they published the wrong models online, and somehow released half-baked early internal releases”.
Official representatives at Meta quickly denied that they trained their models on test sets, which should have led to better benchmarks. So what did they do then? They made two versions of all Llama 4 models, where one version was specifically optimized to be “super friendly” and format text in such a way that most humans appreciated it compared to more formal texts. So while they did not train on benchmarks, they clearly hacked the benchmark system. So if you wondered why Metas chief LLM scientist resigned just days before the Meta 4 launch this might explain it. If you are not familiar with LMArena, it’s a benchmark where two LLMs write output and humans decide which one they liked best. And most users preferred the output from the “hacked” Llama 4 version due to the presentation, even if the content was poor.
LMArena removed the “hacked Llama 4” benchmarks from their website and added the regular Llama 4, and it now scores #32 of all models. I won’t try to speculate into why the regular Llama 4 models perform as bad as they do, but we do know that Llama 4 was delayed several times, and that Meta got inspired by the Mixture-of-Experts architecture of DeepSeek. Maybe they tried some late-minute architectural changes and it just fell flat, and to avoid having to push the release another 6 months forward and not loose face they tried to hack the benchmarks.
Among other news: On Wednesday last week Google announced that they also will support MCP, so it seems we do have a standard protocol for AI agents now. Together with the new Agent2Agent framework by Google (see below) we have most of the puzzle pieces we need to roll out some really amazing agent solutions this year. Both Supabase and Elevenlabs launched MCP servers last week, and I will stop reporting all these MCP servers because soon everyone will be on board. Microsoft released an AI environment called debug-gym which allows AI software development agents to set breakpoints to pause code execution, step through code line by line, and check variable values at different points. As a result all models became 30 – 180% better at fixing bugs, very similar to human developers that stop using command line output for debugging and starts stepping through the code one line at the time. 😂
Thank you for being a Tech Insights subscriber!
THIS WEEK’S NEWS:
- Google Cloud Next 25 Brings AI Agent Ecosystem and Infrastructure Advancements
- Amazon Launches Nova Sonic: Speech-to-Speech Model for Natural Conversations
- Microsoft Transforms Copilot into a Personalized AI Companion
- ChatGPT’s Memory Feature Gets Major Upgrade to Reference All Past Conversations
- OpenAI Launches Evals API for Programmatic Model Testing
- OpenAI Launches BrowseComp to Test AI Agents’ Internet Search Capabilities
- Supabase Launches MCP Server for AI-Database Integration
- Microsoft Releases Debug-Gym to Help AI Learn Debugging Skills
- Canva Launches Visual Suite 2.0 with Advanced AI Features at Canva Create 2025
- ElevenLabs Releases MCP Server for AI Voice Integration
- Cloudflare Launches AutoRAG: Fully Managed RAG Pipeline for AI Applications
Google Cloud Next 25 Brings AI Agent Ecosystem and Infrastructure Advancements
https://cloud.google.com/blog/topics/google-cloud-next/next25-day-1-recap
The News:
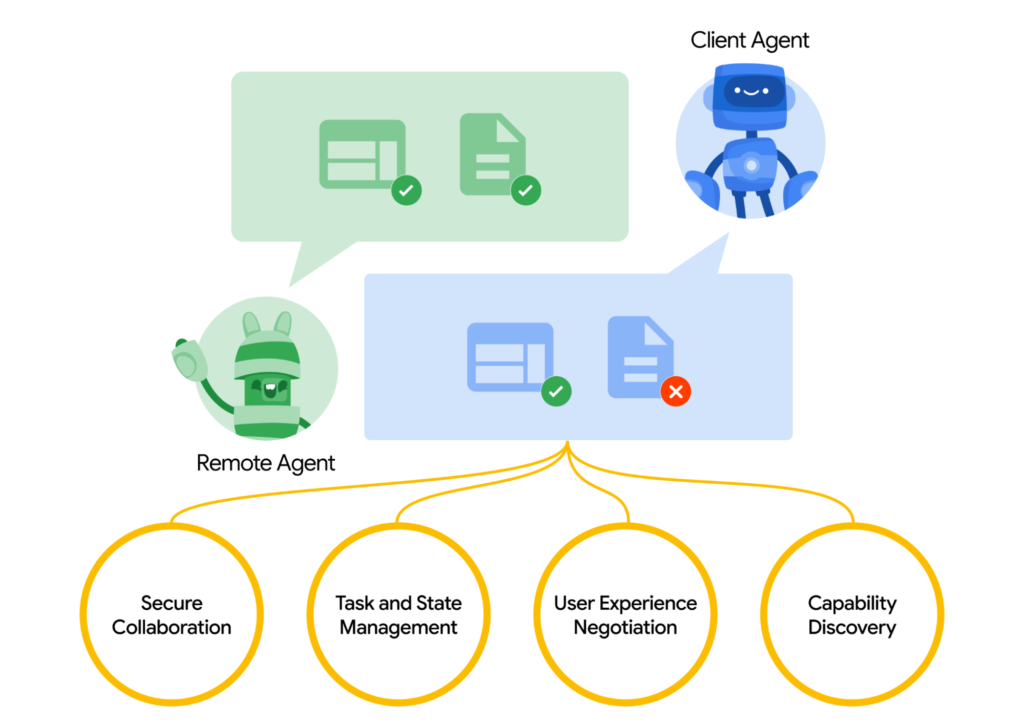
- At Google Cloud Next 25 last week, Google launched a new AI agent ecosystem called Agent2Agent (A2A) Protocol, an open standard enabling AI agents to communicate across platforms, developed with more than 50 partners including Salesforce, MongoDB, and ServiceNow.
- Google also announced Ironwood, Google’s seventh-generation TPU, achieving 3,600 times better performance than their first publicly available TPU while becoming 29 times more energy efficient, designed specifically for inference workloads to power the next generation of AI models.
- Firebase Studio, now in preview, offers a cloud-based development environment with Gemini integration, allowing developers to create full-stack applications through prompts or choose from over 60 templates.
- Google Workspace received significant AI upgrades including audio capabilities in Docs for creating podcast-style overviews, “Help me analyze” in Sheets for automatic data insights, and Workspace Flows for creating automated workflows across applications.
- Gemini 2.5 Pro is now available to developers through the Gemini API, with Gemini 2.5 Flash coming soon, while Veo 2 video generation has reached general availability at $0.35 per second of generated video.
What you might have missed: Google says that “To block the use of your prompts and responses for model training, do not use the App Prototyping agent, and do not use Gemini in Firebase within Firebase Studio. To block the use of your code for model training, turn off code completion and code indexing in your Firebase Studio settings”. I recommend that you do not use Firebase Studio for anything remotely sensitive at this point.
My take: The new Agent2Agent Protocol is the main takeaway for me from Cloud Next. It features things like Capability Discovery, where an agent can advertise their capabilities allowing other agents to find the most suitable collaborators for specific tasks. It also features Task Management, where agents can exchange quick updates or collaborate on multi-stage processes while staying synchronized. The main advantage of this protocol is that agents working in different frameworks can collaborate on shared tasks. For example in a recruitment scenario one agent working in one framework might handle resume screening, another agent in another framework could conduct initial interviews, and a third in a separate framework could perform background checks – all coordinating through the A2A protocol. This is the cross-platform, cross-vendor agent protocol we have been waiting for!
And while Ironwood is fast, the main benefit with Ironwood is that each chip now has 192GB of high-bandwidth memory (HBM) per chip, a 6x increase in memory capacity compared to Google’s previous generation Trillium TPU. Ironwood can be scaled up to a maximum of 9,216 chips in a single POD, which means a configuration up to a staggering 1.7 ExaBytes of HBM available over the TPU’s high-speed Inter-Chip Interconnect. Insane figures opening up so many possibilities for future models.
Amazon Launches Nova Sonic: Speech-to-Speech Model for Natural Conversations

The News:
- Amazon has launched Amazon Nova Sonic, a new speech-to-speech model that unifies speech understanding and generation into a single system, enabling more natural AI voice interactions.
- The model captures nuances of human speech including tone, inflection, and pacing, allowing for deeper understanding of conversational context and intent.
- Nova Sonic processes speech directly without converting to text first, reducing latency and preserving important vocal cues that might be lost in text-based processing.
- The technology enables developers to build applications with more responsive and human-like voice interactions, such as customer service bots, virtual assistants, and other voice-driven interfaces.
My take: Nova Sonic seems very close in performance to OpenAI 4o Voice Mode. Right now it only supports English language with three voice options, and it requires integration with Amazon Bedrock for implementation. So why would you use it? It’s 80% cheaper than GPT-4o. If you have time I recommend checking out their demo, it’s actually quite impressive. Nova Sonic is not yet available in the EU (only US East AWS Region), but once it’s out this should be one of your top candidates if you are developing voice assistants.
Microsoft Transforms Copilot into a Personalized AI Companion
https://blogs.microsoft.com/blog/2025/04/04/your-ai-companion

The News:
- Microsoft has enhanced Copilot with several new features designed to make it a more personalized AI assistant, marking a significant evolution in how users interact with AI technology.
- The new Memory feature allows Copilot to remember user preferences, interests, and personal details like “your favorite food, the types of films you enjoy and your nephew’s birthday” to provide tailored solutions and proactive suggestions.
- Actions capability enables Copilot to complete tasks on behalf of users, such as booking event tickets, making dinner reservations, or sending gifts, working with partners including Booking.com, Expedia, OpenTable, and others.
- Copilot Vision brings real-time visual analysis to mobile devices and Windows, allowing users to interact with their surroundings like scanning rooms for decoration tips.
- Additional features include Pages for organizing content, AI-generated Podcasts for personalized audio content, Shopping assistance for product research and deals, and Deep Research for complex multi-step research tasks.
My take: The new memory feature of Copilot seems identical to ChatGPT’s memory function that was introduced in September last year, and it’s great that it’s now also available for Copilot users. However Copilot always seem to trail quite far behind ChatGPT. As an example, on Thursday last week OpenAI announced that ChatGPT now remembers ALL past conversations, not just specific memory fragments. I wonder if it will take another 6 months before this feature is being rolled out to all Copilot users. Early testing of Copilot Podcasts reveals limitations compared to Google’s NotebookLM, with users reporting that Copilot’s audio sounds “robotic and synthesized”, lacking natural pauses and expressive cues, and The Windows Forum wrote that they felt the dialogue sounded like a “scripted daily briefing” rather than an engaging conversation.
My recommendation now is the same as it has been the past year – don’t lock yourself to a single AI provider. Microsoft might seem like the safe bet (just “switch it on”) but they are behind in almost every single area when it comes to AI. If you want the best AI services today you need seriously consider all AI providers like Anthropic, Elevenlabs, Google, OpenAI and Mistral. There will not be a point in time in the next 2-3 years where one single provider offers the best options in every single area, it will be the exact opposite. If you want maximum ROI from your AI investments you need to be open for alternatives.
ChatGPT’s Memory Feature Gets Major Upgrade to Reference All Past Conversations
https://twitter.com/OpenAI/status/1910378768172212636
The News:
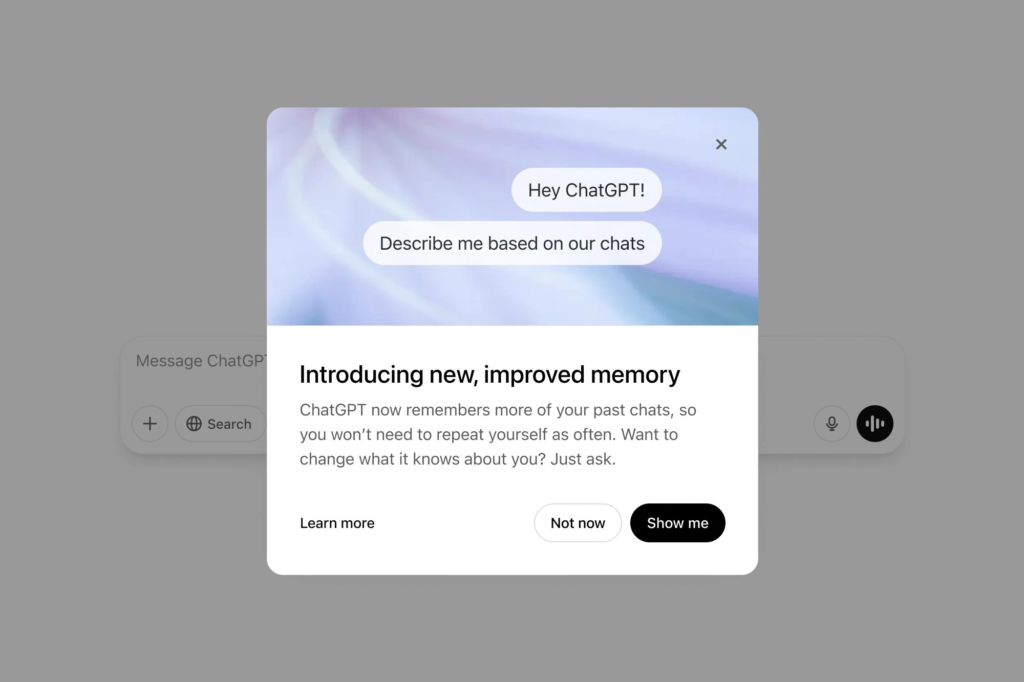
- OpenAI has rolled out an enhanced memory feature for ChatGPT that allows the chatbot to reference and learn from all your previous conversations, creating more personalized and contextually relevant responses.
- The update builds upon the previous memory capability introduced last year, now operating in two ways: through explicitly “saved memories” and through “reference chat history” which automatically draws insights from past dialogues.
- The feature appears in ChatGPT settings as “Reference chat history” and applies to text, voice, and image generation, eliminating the need to repeat information you’ve already shared.
- The rollout is initially limited to ChatGPT Plus and Pro subscribers, with Enterprise, Team, and Edu versions receiving the update “in a few weeks,” though availability is excluded in the UK, EU, Iceland, Liechtenstein, Norway, and Switzerland due to regulatory requirements.
My take: Full memory from all previous conversations is a bigger improvement than most people think. I personally think it’s a complete game-changer and it will change both how we use chatbots but also what we use them for. The more you use ChatGPT the better it will be at understanding you and your needs, and the better ChatGPT gets (new models) the better your investment into it will be. I think it will trigger a positive use case spiral where people put more and more information into ChatGPT which will make it much better which will make everyone put even more information there. Google Gemini got a similar memory feature in February 2025 which is nearly identical (icognito chats vs temporary chats). Anthropic Claude is behind yet again (they were among the last to add web search) and lack any kind of memory system, but I am guessing they will do something like this too in the coming year.
OpenAI Launches Evals API for Programmatic Model Testing
https://platform.openai.com/docs/guides/evals
The News:
- OpenAI has released the Evals API, allowing developers to programmatically define tests, automate evaluation runs, and iterate rapidly on prompts and model implementations within their own workflows.
- The API follows a hierarchical structure with two primary abstractions: Eval Configuration (containing data source schema, testing criteria, and metadata) and Eval Runs (individual evaluation executions with specific data samples and results).
- Developers can create comprehensive evaluations with multiple criteria, including accuracy evaluation using model-based judgment, conciseness evaluation, and reference comparison when applicable.
- The framework enables reusability across multiple testing scenarios while maintaining consistency in evaluation standards, similar to having unit tests for traditional software.
My take: How do you know how well your AI model is performing? You evaluate it. There are dozens of frameworks for this today, such as Helicone, Promptfoo, PromptLayer, Traceloop, and many more. The main advantage with the OpenAI Evals API is that it is directly integrated with OpenAI’s ecosystem, making it easier to log and evaluate OpenAI outputs. That’s also the disadvantage, it’s restricted to teams only using OpenAI APIs. If you are exclusively using OpenAIs models today and want to systematically improve your LLM application’s quality and compare different prompt strategies, then the Evals API is probably your best choice today. If you use or plan to use other models however you might want to look into other frameworks.
OpenAI Launches BrowseComp to Test AI Agents’ Internet Search Capabilities
https://openai.com/index/browsecomp

The News:
- OpenAI has open-sourced BrowseComp, a new benchmark containing 1,266 challenging problems designed to test AI agents’ ability to locate hard-to-find information across the internet.
- The benchmark focuses on questions requiring AI to search tens or hundreds of websites to find answers that are difficult to locate but easy to verify once found.
- Even advanced models struggle with BrowseComp’s challenges—GPT-4o achieved only 0.6% accuracy, GPT-4o with browsing reached 1.9%, and GPT-4.5 scored 0.9%, while OpenAI’s Deep Research model achieved 51.5% accuracy.
- Human evaluators could only solve 29.2% of the problems, with most giving up after approximately two hours of searching, highlighting the benchmark’s difficulty.
- BrowseComp covers diverse topics including TV shows, movies, science, technology, art, history, sports, music, video games, geography, and politics.
My take: I am quite sure that you, like myself, have spent countless hours in front of your computer trying to Google your way info finding something on the Internet, only to give up since you are not able to click your way through the web of links to find the right path. As I have written many times before, I am quite sure we will not browse the web at all like we do today. I believe that in the near future we will mostly use the web to consume information or media, not to search for information. This browser test was interesting in that human evaluators could only solve 29.2% of all problems, and Deep Research could solve 51.5%. We are already at the point where AI models are better than browsing the web than most humans, and it will only improve from here.
Supabase Launches MCP Server for AI-Database Integration
https://supabase.com/blog/mcp-server

The News:
- Supabase has released an official Model Context Protocol (MCP) server that enables AI tools like Cline, Cursor and Claude to directly interact with Supabase databases and perform tasks including launching databases, managing tables, and querying data.
- The MCP server includes over 20 tools that allow AI assistants to design tables, track them with migrations, fetch data using SQL queries, create database branches, spin up new projects, and generate TypeScript types based on database schemas.
- Setup requires creating a personal access token (PAT) and configuring your AI client with a JSON snippet that connects to the Supabase MCP server.
- The integration eliminates the need to switch between multiple tools, as developers can now use natural language commands to have AI assistants execute database operations directly.
- Future plans include adding capabilities to create and deploy Edge Functions directly from AI assistants and implementing native authorization through OAuth 2 login flows.
My take: My typical AI development process now is Claude (architecture planning) -> Claude Code (MVP) -> Cursor. Being able to access Supabase using MCP makes things so much easier, especially when starting up new prototype projects. If you have the time, go check their launch video, it’s just 2 minutes but shows you pretty well what you can do with this. In practice, having MCP means that the LLM can easily retrieve accurate schema information before generating SQL, and execute the queries it generates directly against your database. This is huge, because previously LLMs had very limited context about your database structure and relationships. Before the end of 2025 I predict most services with APIs will have MCP access, and this be the foundation for the next generation of AI agents coming later this year.
Read more:
Microsoft Releases Debug-Gym to Help AI Learn Debugging Skills
The News:
- Microsoft Research has released debug-gym, an environment that allows AI coding tools to learn interactive debugging skills similar to human programmers.
- Debug-gym expands an agent’s capabilities by providing access to debugging tools like pdb (Python debugger), enabling AI to set breakpoints, navigate code, print variable values, and create test functions.
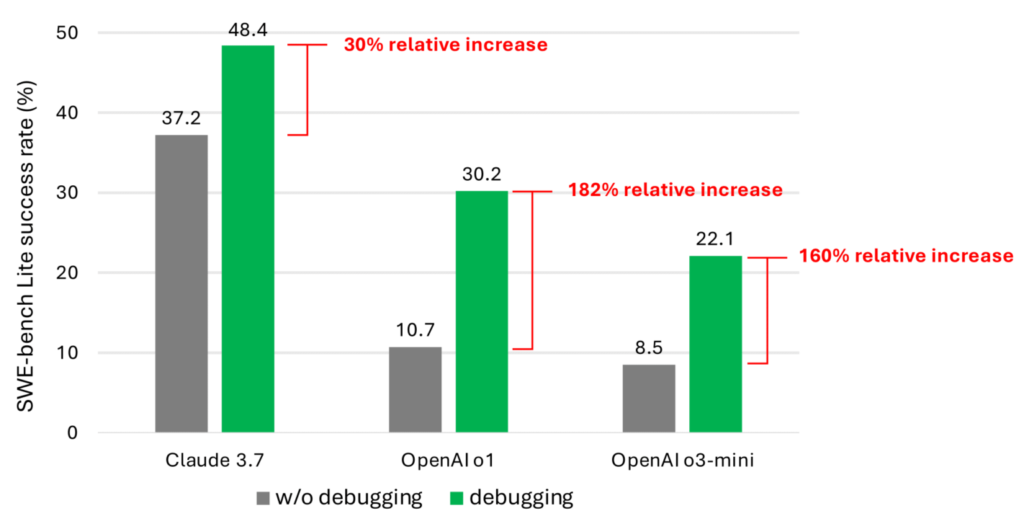
- Testing with Claude 3.7 Sonnet showed promising results, improving performance on SWE-bench Lite from 37.2% without debugging tools to 48.4% with debugging tools, and 52.1% when using a hybrid approach.
- The environment includes three coding benchmarks to measure performance: Aider for simple function-level code generation, Mini-nightmare for hand-crafted buggy code examples, and SWE-bench for real-world coding problems.
- Microsoft has open-sourced debug-gym to facilitate research toward building interactive debugging agents that can seek information by interacting with code environments.
My take: Wow, what an improvement! Going from 37.2% to 48.4% in success rate in debugging tasks is huge! debug-gym gives LLMs access to the same debugging tools human programmers use – like setting breakpoints to pause code execution, stepping through code line by line, and checking variable values at different points. This is the first of it’s kind, and before debug-gym all debugging by LLMs was done by just reading the code and collecting console output. Even if you are the best developer in the world, this is not the way you approach debugging. I’m very enthusiastic about debug-gym, and with a few iterations LLMs will soon be as good at debugging software as they are writing code.
Canva Launches Visual Suite 2.0 with Advanced AI Features at Canva Create 2025

The News:
- Canva launched Visual Suite 2.0 last week, the company’s largest product launch since its founding in 2012.
- Visual Suite in One Design allows users to create documents, presentations, and websites in a single unified format, eliminating the need for separate tools and disconnected files.
- Canva Sheets reimagines spreadsheets with visual elements and AI-powered features like Magic Insights, which automatically identifies patterns in data, and Data Connectors that import information from platforms like Google Analytics and HubSpot.
- Canva AI serves as a voice-enabled conversational creative partner that brings all of Canva’s generative AI tools into one workflow, enabling users to generate text, slides, images, and edit photos through simple prompts.
- The company has grown to 230 million monthly active users, with 35 billion designs created since 2013 and an annualized revenue exceeding US$3 billion, representing a 30% increase over the past year.
My take: I have tried to use Canva several times for small designs but typically always fall back to Illustrator and Photoshop. But this new version looks quite interesting. Canva is mixing sheets, visual design and generative AI together in a tool that makes creating almost any content easy and collaborative. I can see Visual Studio in One Design and Canva Sheets becoming more or less the defacto-standard by students for easily creating good looking charts and designs in a very easy to use package. Do you use Canva today? I’d love to hear your input on these new releases!
ElevenLabs Releases MCP Server for AI Voice Integration
https://github.com/elevenlabs/elevenlabs-mcp

The News:
- ElevenLabs has launched its official Model Context Protocol (MCP) server, enabling Claude Desktop, Cursor, Windsurf, and OpenAI Agents to access advanced text-to-speech and audio processing capabilities through simple text prompts.
- The server supports text-to-speech generation, voice cloning, audio transcription, speaker identification, and soundscape creation without requiring users to write custom API integration code.
- Users can create AI voice agents capable of making outbound calls, generating audiobooks, and producing immersive audio environments for applications in gaming, virtual reality, and film production.
My take: I think this is the last “Company X now has an MCP server” that I will post. I was unsure about MCP when Anthropic launched the standard late last year, but it has taken the market by storm and now every provider including Google and OpenAI will soon support it throughout all their products. It means that quite soon any AI model will be able to perform almost any task in any system.
Cloudflare Launches AutoRAG: Fully Managed RAG Pipeline for AI Applications
https://blog.cloudflare.com/introducing-autorag-on-cloudflare

The News:
- Cloudflare has released AutoRAG in open beta, a fully managed Retrieval-Augmented Generation pipeline that simplifies integrating context-aware AI into applications by automating the complex process of building RAG systems.
- AutoRAG handles the entire RAG pipeline automatically: ingesting data, chunking and embedding it, storing vectors in Cloudflare’s Vectorize database, performing semantic retrieval, and generating responses using Workers AI.
- The system continuously monitors data sources and indexes in the background, ensuring AI stays current without manual intervention, making it suitable for AI-driven support bots, internal knowledge assistants, and semantic search across documentation.
- AutoRAG currently supports integration with Cloudflare R2 for data storage, with plans to expand to direct website URL parsing and structured data sources like Cloudflare D1 throughout 2025.
- During the open beta period, AutoRAG is free to enable, with no additional costs for compute operations related to indexing, retrieval, and augmentation.
My take: If you are a company with no AI expertise but want to get started with AI agents and RAG, then this might be a good option. In a video posted by Cloudflare they show how to create a complete RAG system in under 10 minutes without writing any code at all. Currently it only supports R2 buckets as data sources, which limits its immediate utility for organizations with data in other formats and locations. Cloudflare announced that they plan to add support for more data source integrations in the near future, including support for direct website URL parsing and structured data sources like Cloudflare D1. For most companies I still recommend that you contact a specialized AI agent company to help you get started. It’s not that difficult to set up a RAG pipeline correctly, and doing it yourself means you can integrate with any data, any place.
Read more: