
“There is no wall — inference compute continues to scale” said OpenAI after they announced o3 last Friday, which performs better than humans on one of the benchmarks for Artificial General Intelligence (AGI)! 🤯
The past week showed some truly amazing AI innovations. Google launched Veo 2 and Imagen 3 that produce some of the best AI generated videos I have seen so far. Pika Labs launched version 2.0 with a new feature called “Scene Ingredients” that is amazingly good – check the videos below. Over 20 research laboratories collaborated for two years and finally launched “Genesis”, a new open-source physics engine that is between 10x-80x times faster than current state-of-the-art models. NVIDIA launched a portable and palm-sized AI supercomputer for only $249, and ElevenLabs launched a new multimodal language model with only 75 milliseconds latency, providing truly next-generation callcenter experiences!
These were just the top news, and there are much, much more, so grab a cup of coffee and dive into the news!
THIS WEEK’S NEWS:
- OpenAI Unveils Next-Generation Reasoning Models o3 and o3-mini
- Google Launches Next-Gen AI Tools for Video and Image Creation
- ElevenLabs Launches Flash v2.5: Ultra-Fast Text-to-Speech in 32 Languages
- Genesis: New Open-Source Physics Engine
- Pika Labs Launches 2.0 with Advanced AI Video Generation Features
- NVIDIA Launches $249 Palm-Sized AI Supercomputer
- Microsoft Releases Small Model Phi-4 that Beats GPT-4o in Math
- GitHub Announces Free Plan for GitHub Copilot
- Google Launches Gemini 2.0 Flash “Thinking Mode”
- Odyssey Unveils Explorer: AI-Powered 3D World Generation from Images
- Meta Introduces Apollo: A New Family of Video Language Models
- Apple Urged to Cancel AI Feature after False Headlines
- OpenAI Launches o1 API
OpenAI Unveils Next-Generation Reasoning Models o3 and o3-mini
The News:
- OpenAI introduced o3 and o3-mini, two new AI models designed for enhanced reasoning, coding, and problem-solving. The company skipped “o2” due to a potential copyright conflict with British telecom O2.
- The o3 model showed some amazing benchmark scores, including 71.7% accuracy in SWE-bench verified coding tests, 96.7% on AIME 2024 mathematics exam, and 87.7% on PhD-level science questions (GPQA Diamond).
- The o3-mini variant offers three different processing speeds (low, medium, and high) and is designed as a cost-efficient alternative that can adapt its reasoning time based on task complexity.
- Availability: o3-mini is planned for release by the end of January 2025, with the full o3 to be launched later. OpenAI is currently accepting applications for safety testing from researchers until January 10.
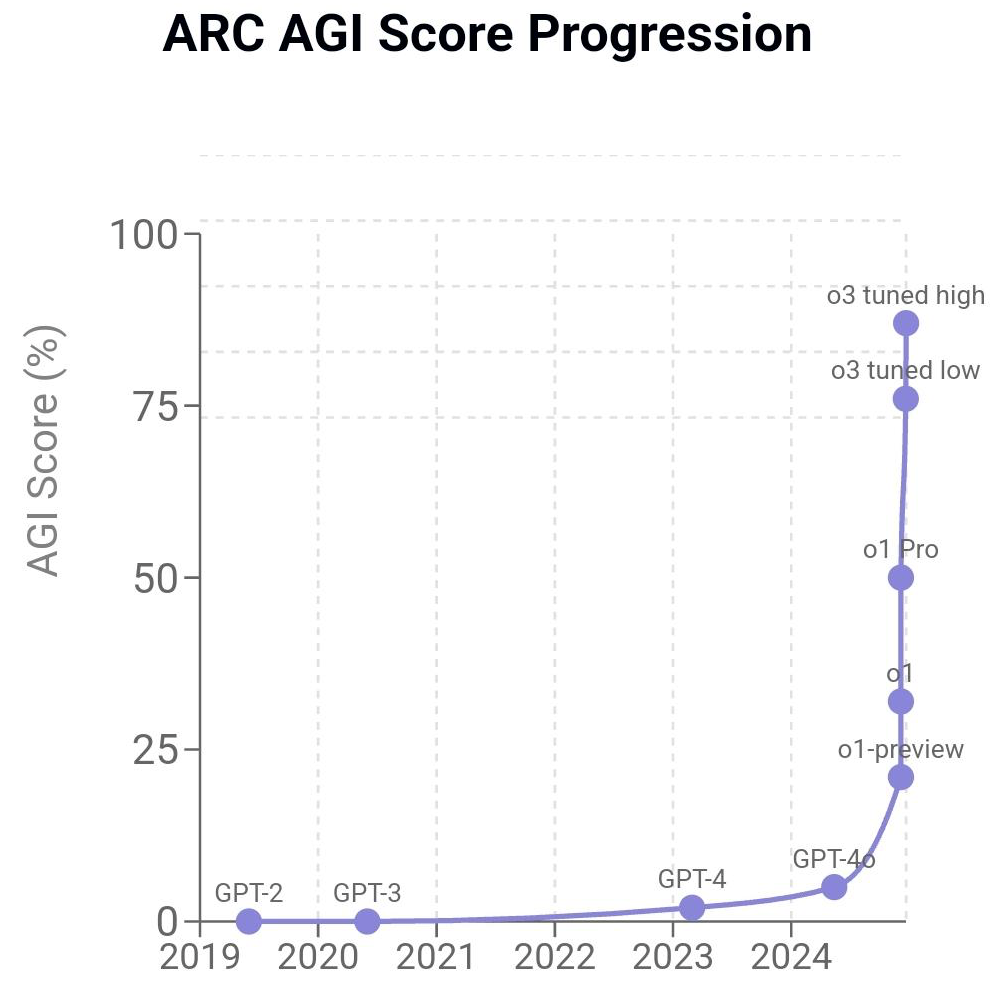
What you might have missed: François Chollets, creator of Keras and author of the influential paper “On the Measure of Intelligence” where he introduced the “Abstract and Reasoning Corpus for Artificial General Intelligence” (ARC-AGI) benchmark, just posted a lengthy blog post about the amazing achievement of o3, saying ”All intuition about AI capabilities will need to get updated for o3”. This post is highly recommended for anyone interested in AI and Machine Learning.
My take: If you saw Ilya Sutskever’s talk at Neurips 2024 on December 14, he declared that “LLMs scaling has plateaued”. Now, less then a week later, OpenAI launches o3 and their Head of Product Nicholas Turley states that there is no wall – inference compute continues to scale. The upcoming model o3 even scored 87.5% on the ARC-AGI benchmark (see image above), surpassing the human-level threshold of 85%, showing an incredible improvement in AI’s ability to learn and adapt to new tasks. Our journey in AI has truly just begun.
Read more:
- OpenAI unveils o3 and o3 mini — here’s why these models are a giant leap | Tom’s Guide
- OpenAI o3 Breakthrough High Score on ARC-AGI-Pub
Google Launches Next-Gen AI Tools for Video and Image Creation
https://blog.google/technology/google-labs/video-image-generation-update-december-2024

The News:
- Last week Google introduced Veo 2 and Imagen 3, its latest AI models for video and image generation, together with a new experimental tool called Whisk. The tools are available through Google Labs’ VideoFX and ImageFX platforms.
- Veo 2 creates high-quality videos up to 4K resolution with improved understanding of physics and human movement. The model can interpret cinematographic instructions, allowing users to specify lens types, camera angles, and effects like “shallow depth of field”.
- Imagen 3 creates images with different artistic styles, from photorealism to anime. Imagen 3 shows better prompt adherence and richer details than version 2, outperforming competitive models in human evaluations.
- Whisk, a new experimental tool, combines Imagen 3 with Gemini’s visual capabilities to help users remix and transform images into different styles like digital plushies or stickers.
- Availability: Veo 2 and Whisk are currently only accessible to users in the United States. Imagen 3 is available globally through ImageFX or through Gemini in over 100 countries.
My take: I was quite disappointed with the performance of OpenAI Sora when it launched two weeks ago, but from what I have seen so far from Veo 2 it’s everything I hoped Sora would be and much more. With Google owning Youtube I guess it was just a matter of time before they started to dominate the text-to-video scene, and the progress we have seen in video generation just the past year has been nothing short of incredible. If you have time, check some of the links below, these are truly some next-level AI animations.
Read more:
- Agrim Gupta on X:”A pair of hands skillfully slicing a ripe tomato on a wooden cutting board”
- (19) Nathan Lands — Lore.com on X: “13 game-changing Veo 2 examples that’ll blow your mind:” / X
- Google Veo 2 Demo – Physics Test – YouTube
ElevenLabs Launches Flash v2.5: Ultra-Fast Text-to-Speech in 32 Languages
https://elevenlabs.io/blog/meet-flash

The News:
- ElevenLabs just introduced Flash v2.5, a new text-to-speech model that transforms text into speech in just 75 milliseconds, making it one of the fastest AI voice models currently available.
- The model supports 32 languages and is specifically designed for real-time applications and conversational AI.
- Availability: ElevenLabs Flash 2.5 is available globally, including all EU countries.
My take: What an amazing achievement! The modal conversational response time of humans is around ~200 milliseconds in an active dialogue, so this is the target latency we want to reach for a discussion to “feel natural”. However, if you are using a Bluetooth headset connected to your computer or phone, even the latest AirPods Pro 2 adds 126 milliseconds of latency. This means that on a 5G connection using a Bluetooth headset you will get at least 282 milliseconds of latency (funny thing, if you use Microsoft Teams and both sides use wireless headphones the total roundtrip latency is always at least 500 milliseconds on WiFi, so that explains why you always seem to interrupt each other when everyone uses a Bluetooth headset). Bringing the latency of the LLM down to 75 milliseconds means that the total latency will be around 350 milliseconds when using wireless headphones on a cellular network, which is about as close to a natural discussion we can come, and much better than having a Teams call or a call center host on Bluetooth headphones with a total roundtrip latency over half a second.
Genesis: New Open-Source Physics Engine
https://genesis-embodied-ai.github.io

The News:
- Genesis is a new physics simulation platform designed for robotics and AI applications, developed through collaboration between 20+ research laboratories over two years.
- The platform achieves amazing simulation speeds, running at 43 million FPS (430,000 times faster than real-time) when simulating a manipulation scene with a single plane and a Franka arm on a single RTX 4090.
- Built entirely in Python, Genesis integrates multiple physics solvers to simulate various phenomena including rigid bodies, fabrics, liquids, smoke, and deformable materials. It is also 10-80x faster than existing solutions like Isaac Gym and MJX.
- Genesis features a VLM-based generative agent that can autonomously create 4D dynamic worlds from natural language descriptions, enabling the generation of interactive scenes, task proposals, and robot behaviors without manual intervention.
- Availability: The team has open-sourced the underlying physics engine and the simulation platform, with access to the generative framework to be rolled out gradually in the near future.
My take: Wow, what an amazing achievement! It’s very hard to try to summarize everything Genesis does, so if you have time please visit their website and just scroll through the page examples. Genesis has the potential to dramatically accelerate robotics research and development by reducing the time and expertise needed to create complex training scenarios. This might be the missing puzzle piece we need to get robots that actually perform better than humans in most tasks.
Read more:
Pika Labs Launches 2.0 with Advanced AI Video Generation Features

The News:
- Pika Labs just released Pika 2.0, an AI-powered video generation tool that allows users to create customized videos through text prompts and image uploads. Pika has already attracted over 11 million users with more than 2 billion video views.
- The standout new feature is “Scene Ingredients,” which enables users to upload and blend their own images of characters, objects, and backgrounds. Users can create scenarios like “surfing cats in space” by combining different visual elements.
- The new version also offers improved “text alignment capabilities”, making it easier to transform detailed prompts into accurate video clips. Motion rendering has been enhanced to provide more natural movement and realistic physics.
- Unlike competitors like OpenAI Sora focusing on professional studios, Pika 2.0 targets individual creators and small brands, positioning itself as an affordable alternative for social media content creation. Several major brands including Balenciaga, Fenty, and Vogue have already adopted Pika’s tools for creating social media advertisements
- Availability: Pika 2.0 is available globally, including all EU countries.
My take: Available to use in the EU? Check! Pika 2.0 is amazingly fun to play around with, give it two images and a text prompt and post your results in a comment to this newsletter on LinkedIn! Also, if you have two minutes check out the amazing examples below!
Read more:
- Min Choi on X: “This is wild. Pika 2.0 with Scene Ingredients feature is insane! 10 wild examples
- Generative AI on LinkedIn: #ai #openai #sora #pikalabs
- Pika challenges OpenAI and Sora with new AI video generator features | TechRadar
NVIDIA Launches $249 Palm-Sized AI Supercomputer
https://blogs.nvidia.com/blog/jetson-generative-ai-supercomputer/

The News:
- NVIDIA just unveiled the Jetson Orin Nano Super Developer Kit, a compact generative AI ”supercomputer” that fits in the palm of a hand, now available at $249 (reduced from $499).
- The device delivers 1.7x better generative AI performance compared to its predecessor, with a 70% increase in performance to 67 INT8 TOPS and 50% higher memory bandwidth at 102GB/s.
- The hardware features an NVIDIA Ampere architecture GPU with 1024 CUDA cores, 32 tensor cores, and a 6-core ARM CPU, along with 8GB LPDDR5 memory.
- Developers can use it to run popular AI models from Google, OpenAI, and Microsoft, making it suitable for applications in robotics, smart surveillance, autonomous vehicles, and AI-powered smart devices. The device operates at just 25 watts of power consumption.
- Availability: Now.
My take: Jetson Orin Nano Super is great news for anyone interested in edge AI computing, in particular schools, students and small businesses with limited budgets. The price reduction from $499 to $249 should allow more people globally to start experimenting with AI, and will hopefully bring lots of exciting new innovations to the market in the coming years. NVIDIA also recently announced an extension of the product lifecycle of Jetson Orion to 2032, which clearly shows that this is a platform they will focus on for years to come.
Read more:
Microsoft Releases Small Model Phi-4 that Beats GPT-4o in Math
The News:
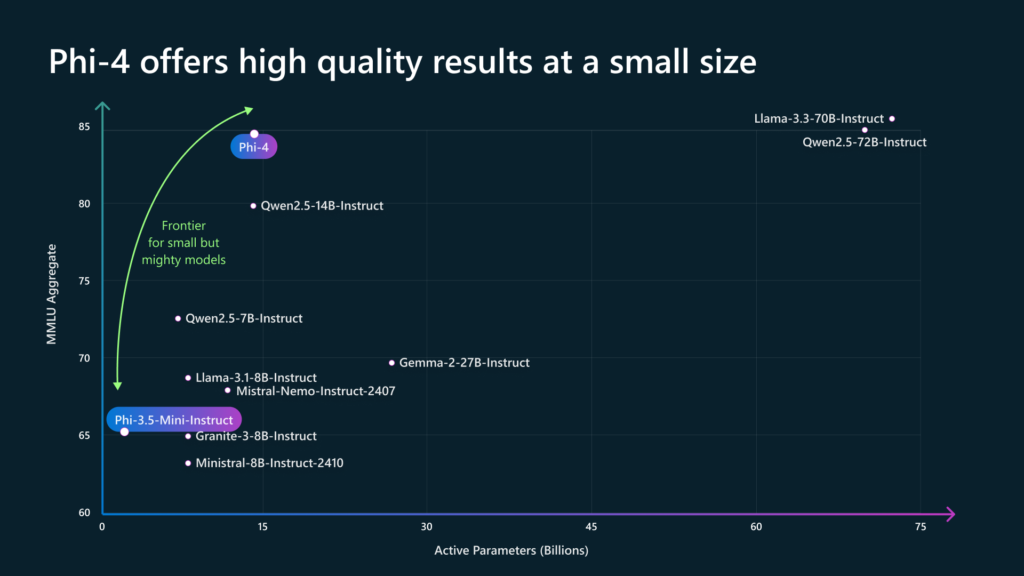
- Microsoft just released Phi-4, a 14B parameter small language model that outperforms competitors like GPT-4o and Gemini Pro 1.5 in areas like mathematical reasoning, despite being much smaller in size.
- Microsoft trained Phi-4 primarily on synthetic data, using AI to generate and validate approximately 400B tokens of high-quality training material.
- The model also features an upgraded mechanism that can process longer inputs of up to 4,000 tokens, double the capacity of Phi-3.
- Availability: Phi-4 is available in a limited research preview on Azure AI Foundry, and a wider release is planned for Hugging Face.
My take: Both Microsoft and Meta are investing heavily in the small language model approach, and it’s easy to understand why. With Phi-4 surpassing GPT-4o on graduate-level STEM Q&A and math competition problems despite being a fraction of the size it will be very interesting to see just how far we can push these smaller models next year.
GitHub Announces Free Plan for GitHub Copilot
https://code.visualstudio.com/blogs/2024/12/18/free-github-copilot

The News:
- GitHub just announced a free tier of its AI-powered coding assistant Copilot for Visual Studio Code users, requiring only a GitHub account with no credit card or subscription needed.
- The free plan includes 2,000 code completions per month (approximately 80 per working day) and 50 chat requests monthly, with access to both GPT-4o and Claude 3.5 Sonnet.
- Users can work with multiple files simultaneously using Copilot Edits, which can propose changes and create new files based on natural language prompts.
- New features include voice chat capabilities, terminal assistance, automatic commit message generation, and custom coding instructions that can be shared across teams.
- A preview feature called Vision Copilot will allow developers to generate interfaces based on screenshots or markup, though it currently requires a separate API key.
- GitHub also announced its 150M developer milestone, up from 100M in early 2023.
- Availability: GitHub Copilot Free is available globally, including all EU countries.
My take: In June 2024 I stopped writing code by hand and has since then been writing thousands of lines of code 100% using different AI tools. My current favorite is Cursor, mainly due to its small local models that perform multi-line autocomplete and much more, making it a very fun and rewarding environment to work in. GitHub Copilot for Visual Studio Code is quickly catching up, but it’s not there yet in terms of speed and usability. Releasing Copilot for free, including access to both GPT-4o and Claude 3.5 is great news, and will hopefully encourage even more developers to switch to fully AI-generated coding in the near future.
Google Launches Gemini 2.0 Flash “Thinking Mode”
https://ai.google.dev/gemini-api/docs/thinking-mode

The News:
- Google just launched Gemini 2.0 Flash “Thinking Mode”, an experimental model that’s trained to generate the “thinking process” the model goes through as part of its response.
- The model has a 32k token input limit and can handle both text and image inputs, with output limited to 8k tokens in text format.
- Availability: Thinking Mode is available to developers through Google AI Studio and Vertex AI, with two model versions: “gemini-2.0-flash-thinking-exp” or “gemini-2.0-flash-thinking-exp-1219”.
- Gemini 2.0 Flash is currently ranked #1 on the Chatbot Arena.
My take: I know many AI researchers object to the idea that an AI model that perform test-time-compute is “thinking”, but here is Google launching their new models with something they call “thinking mode”. So this is what I will call them from now on: “Thinking AI models”. These models are the future of generative AI, and will probably replace most high-end foundation models during next year. I have been very impressed with all the launches from Google the past weeks, and the new Gemini 2.0 Flash “Thinking Mode” is just icing on the cake.
Read more:
Odyssey Unveils Explorer: AI-Powered 3D World Generation from Images
https://odyssey.systems/introducing-explorer

The News:
- Odyssey Explorer is a generative world model that can transform any 2D image into a detailed, photorealistic 3D environment, complete with motion capabilities and editing support.
- The technology uses Gaussian Splatting for 3D scene representation, which allows for highly detailed scene reconstruction and compatibility with tools like Unreal Engine, Blender, Maya, and After Effects.
- Current generation time averages 10 minutes per scene, with the company actively working on achieving real-time generation capabilities.
- The project has gained significant credibility with Pixar co-founder Ed Catmull joining Odyssey’s board of directors and also investing in the company.
- Garden Studios in London has already tested Explorer in real production workflows for feature films, television, and commercials.
- Availability: Internal tests.
My take: Odyssey looks like a significant step towards automating 3D content creation for film, gaming, and virtual production. There is however a backside to this. A recent Wired investigation found that game studios like Activision Blizzard, which has laid off scores of workers, are using AI to cut corners, ramp up productivity, and compensate for attrition. And a 2024 study commissioned by the Animation Guild, a union representing Hollywood animators and cartoonists, estimated that over 100,000 U.S.-based film, television, and animation jobs will be disrupted by AI by 2026. Art is a craft that takes years to perfect and that can be passed on in generations. Where does it leave us as a society, where art is a skill long forgotten and everything beautiful we see is created by machines?
Read more:
Meta Introduces Apollo: A New Family of Video Language Models

The News:
- Apollo is a new family of open-source video language models developed by Meta, designed to enhance video understanding capabilities in Large Multimodal Models (LMMs).
- Apollo models can process up to an hour long videos, and their smaller model Apollo-3B outperforms most existing 7B models, where the 7B achieves a score of 70.9 on MLVU, and 63.3 on Video-MME.
- Availability: The Apollo models were up for a brief time on HuggingFace but then pulled by Meta. Availability is unclear.
My take: Meta is clearly going the route with multiple smaller specialized models, and in an agentic context this is probably the right way to go. The benefits of running these smaller models are less power consumption, less GPU requirements and the possibility to run locally, and I can definitely see the Apollo series of LLMs being used in many ways to summarize longer videos in different contexts. One such thing could be surveillance cameras, where an Apollo LLM could easily detect if something important happens over footage split into hours.
Read more:
Apple Urged to Cancel AI Feature after False Headlines
https://www.bbc.com/news/articles/cx2v778x85yo

The News:
- Apple’s new AI feature, Apple Intelligence, has generated misleading headlines, including a false story about how Mangione, the man accused of the murder of healthcare insurance CEO Brian Thompson in New York, had shot himself. He has not.
- The feature, launched last week, uses AI to condense and categorize notifications from news articles, emails, and text messages on newer iPhone models running iOS 18.1 or later.
- Reporters Without Borders (RSF) has called for Apple to withdraw the technology, with Vincent Berthier stating “AIs are probability machines, and facts cannot be determined by chance”
My take: I think Apple both overestimated the capabilities of their “Intelligence” and at the same time underestimated the risks of showing incorrect content in summaries. However, in this example case BBC only posted a screenshot of the incorrect summary, not the actual notifications, so it’s impossible to know what was really behind the incorrect summary that made it post the wrong thing. It’s a summary of 22 different notifications so they might as well tried to “hack” it to show the wrong summary, just to get a news article. I think we need to follow this over a few weeks to see where it goes from here, and in the meantime don’t fully trust the summaries if you have them enabled and live outside the EU.
Read more:
OpenAI Launches o1 API
https://openai.com/index/o1-and-new-tools-for-developers

The News:
- OpenAI released its o1 reasoning model to their API, initially available to tier 5 developers who spend at least $1,000 and have accounts older than 30 days.
- The new o1 model features self-checking capabilities that help avoid common AI pitfalls, though it requires more time to generate responses. Pricing is set at $15 per 750,000 words analyzed and $60 per 750,000 words generated, which is 3-6x more expensive than GPT-4o.
- The new version, o1-2024-12-17, shows significant performance improvements, achieving 96.4% accuracy in mathematical tasks and 76.6% in programming tasks, up from 85.5% and 52.3% respectively. The model also uses 60% fewer reasoning tokens than its predecessor o1-preview.
- OpenAI is also rolling out WebRTC support for their Realtime API, making it easier to “build and scale real-time voice products across platforms” such as browsers, mobile apps or IoT devices.
- Availability: OpenAI o1 API is available globally, including all EU countries.
My take: Great news for those who have a need for it. Myself I still find the regular o1 way to cumbersome in daily use, where it typically gives way too much details and struggles with simpler things and writing decent texts. I’m not really sure what the target group for the o1 API is, if you know please give a comment on my newsletter on LinkedIn, I would very much appreciate it! For the upcoming model o3 I better understand the need of an API since it promises to excel in coding. But for o1, not so much.
Read more: