
The greatest news last week was definitely Anthropic’s Computer Use API, which allows their large language model Claude “to perceive and interact with computer interfaces”. In practice Claude can, if you allow it, move your mouse cursor, start applications, browse web pages and type in text. It can also download documents and files, open Visual Studio code and compile software programs. It’s a bit buggy, it crashes, it’s expensive, and yet it’s totally amazing. I have collected a few examples below, and this together with the new ChatGPT Advanced Voice Mode that was just launched in the EU really makes it feel like we have taken a huge step forward in technical advancements, in just one week.
THIS WEEK’S NEWS:
- Anthropic Launches Updated Claude 3.5, Computer Use API and Analysis Tool
- Runway Launches Act-One: Expressive Character Performance
- Apple Launches Hearing Aid Feature for AirPods Pro 2
- Midjourney Launches Image Editor : Generative Fill and Retexture
- Ideogram Launches Canvas
- OpenAI Launches Voice Mode in EU
- Stability AI Releases Stable Diffusion 3.5
- IBM Launches Granite 3.0 : Open Source Enterprise Models
- Meta Launches Mobile-Optimized Versions of Llama 3.2
- New Open Source Video AI Launched : Genmo Mochi 1
- Perplexity Launches Native macOS App
Anthropic Launches Updated Claude 3.5, Computer Use API and Analysis Tool
https://www.anthropic.com/news/3-5-models-and-computer-use

The News:
- Anthropic, the company behind the very popular Large Language Model Claude, just announced three major news the past week:
- First, they significantly upgraded Claude 3.5 Sonnet while keeping the same version number. If you are using Claude for programming you should see a significant increase in code quality with the new version.
- Second, they launched a Computer Use API, which allows Claude “to perceive and interact with computer interfaces”.
- Developers can integrate the Computer Use API to enable Claude to translate instructions (e.g., “use data from my computer and online to fill out this form”) into computer commands (e.g. check a spreadsheet, move the cursor to open a web browser, navigate to the relevant web page, fill out a form, etc).
- Finally, Anthropic also launched an Analysis tool on claude.ai that enables Claude to write and run JavaScript code. This means Claude can now “process data, conduct analysis, and produce real-time insights”. According to Anthropic “Claude now works like a real data analyst. Instead of relying on abstract analysis alone, it can systematically process your data—cleaning, exploring, and analyzing it step-by-step until it reaches the correct result.”
My take: The Computer Use API is a bit buggy, it crashes, it’s expensive, and yet it’s totally amazing. Anthropic does not yet have a native app for MacOS and Windows, so there is a bit of work to get the Computer Use API up and running. But if you have the time it’s totally worth it. Imagine things like searching LinkedIn for candidates, in the very near future you can have Claude browse through thousands of profiles on your computer over night and then give you a summary in the morning. I see so many opportunities with this, but also risks and issues that needs to be resolved. Any website that today tries to detect if you are human or not need to drastically think over their future strategy. While Claude and ChatGPT most probably will have restrictions in place that will prevent them from identifying as humans, many open source models will most probably not have the same restrictions, and they will catch up in performance sooner or later.
Read more:
- Introducing the analysis tool in Claude.ai – Anthropic
- Developing a computer use model – Anthropic
- 10 wild examples of Claude Computer Use
- Top improvements in Claude 3.5 by Alex Albert at Anthropic
Runway Launches Act-One: Expressive Character Performance
https://runwayml.com/research/introducing-act-one

The News:
- Runway just launched Act-One, a new feature for their video generation model that allows users to map recorded human facial expressions to AI-generated characters, using a single video and reference image.
- The system captures “nuanced performances, including micro-expressions and eye movements”, using just a smartphone video and a character reference image.
- Act-One allows creators to transfer the single video performance across multiple AI characters in different styles and angles.
- Access to Act-One will begin gradually rolling out to users and will soon be available to everyone.
My take: Six weeks ago Runway partnered with Lionsgate Studios and now this amazing tool is announced. If you missed the video of this launch do spend 2 minutes of your time to watch the video on their homepage, it’s mindblowingly good!
Apple Launches Hearing Aid Feature for AirPods Pro 2
https://www.theverge.com/24275178/apple-airpods-pro-hearing-aid-test-protection-preview

The News:
- If you own the AirPods Pro 2, you can now take a “Hearing Test” to determine how well your hearing responds to different sound frequencies.
- Once the hearing test is done, you can then ask your iPhone to adjust all sound in the environment to match your hearing loss.
- You can also adjust music, video, phone calls and face time to match your hearing loss.
- All this requires that you have a pair of AirPods Pro 2, but the feature does not cost anything extra.
My take: This feature is so amazingly great that I just had to write about it! According to Apple, 80% of adults in the US haven’t had their hearing checked in at least five years. With a typical set of hearing aids costing up to $6000, it’s easy to understand why. Now anyone can check their hearing at home, and start using their current AirPods Pro 2 as a cheap hearing aid. If the experience is great I have no doubt many people will “move up” to real hearing aids, but this lowers the bar significantly and makes it so much more affordable and accessible! This will improve the lives for so many people!
Read more:
- How Much Do Hearing Aids Cost in 2024?
- CNET: I Tested Apple’s Hearing Aid – YouTube
- Exclusive inside Apple’s audio lab where the company is taking on hearing loss – YouTube
- Apple’s AirPods Pro hearing health features are as good as they sound – The Verge
Midjourney Launches Image Editor : Generative Fill and Retexture
https://twitter.com/midjourney/status/1849213115009056919

The News:
- Midjourney has launched an update to their web based AI image creation tool that allows users to modify, expand and retexture images using text prompts.
- Generative fill and expand works very similarly to Adobe Photoshop or Lightroom Classic, where you erase or expand parts of an image and allow the AI engine fill in the details you describe.
- Retexture is a bit different, you upload an image and using a prompt you can then change the style of the image by describing how you want it to look. The original shape is the same but the details and colors are changed.
- Initial access is limited to yearly subscribers, 12-month members, and users with 10,000+ generations.
My take: Generative fill and expand is almost becoming ubiquitous now, with Google even integrating it straight into the new Pixel phones. Today you cannot trust anything you see digitally, and it will be interesting to see how this will affect us as a society going forward. The new retexture feature was neat, and especially for designers I think it will be a big hit.
Ideogram Launches Canvas
https://about.ideogram.ai/canvas
The News:
- Ideogram just launched Canvas, which enables tools like generative fill and expand much like Midjourney (above).
- Canvas is however more than just “paint to fill” like Midjourney. In Canvas you can upload multiple images, crop, rotate and even merge them together in various ways.
- Ideogram also provides an API for developers to integrate Magic Fill and Extend into their applications.
My take: This tool was pretty neat, if you have 1 minute go check the launch video for a quick introduction on how it works.
OpenAI Launches Voice Mode in EU
The News:
- OpenAI has officially launched Advanced Voice Mode (AVM) in Europe. The rollout includes all Plus subscribers in the European Union, Switzerland, Iceland, Norway, and Liechtenstein.
- Advanced Voice Mode enables natural voice interactions with ChatGPT through mobile phones, laptops, or PC microphones, allowing users to engage in conversational exchanges with the AI assistant.
My take: After I showed Advanced Voice Mode to my family we are now paying for 4 ChatGPT Plus licenses every month 🤯. My kids love it, they use it when studying to quickly ask questions while avoiding having to move focus away from the books. Advanced Voice Mode really do enable new kinds of interaction with technology, and it’s one of the strongest connections you can have with technology that I have experienced. If you are still on the ChatGPT Free plan then I highly recommend that you spend the dollars and buy a test month. It’s like trying VR for the first time, but compared to VR this is something you will probably use more and more as time goes on.
Stability AI Releases Stable Diffusion 3.5
https://stability.ai/news/introducing-stable-diffusion-3-5

The News:
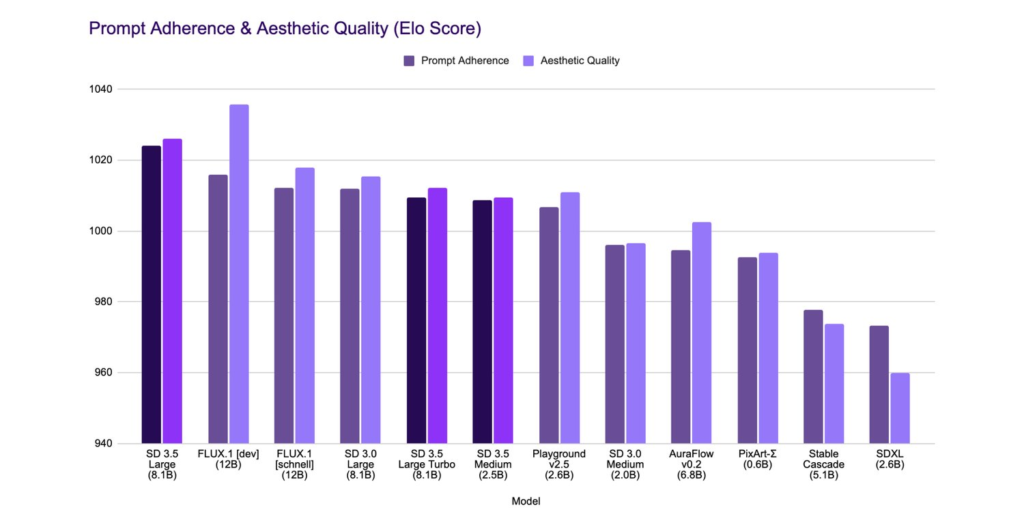
- Stability AI just launched Stable Diffusion 3.5 in three variants: Medium, Large and Large Turbo.
- Stable Diffusion 3.5 Large is an 8-billion parameter model “with superior quality and prompt adherence”.
- Stable Diffusion 3.5 Large Turbo is “considerably faster than Stable Diffusion 3.5 Large”.
- Stable Diffusion 3.5 Medium is coming on October 29 and is a 2.5 billion parameter model designed to run “out of the box on consumer hardware”.
- Key improvements in version 3.5 include: Enhanced text rendering, better realism and image quality, better support for different skin tones and features, and more styles such as 3D, photography and painting.
- Stable Diffusion 3.5 is available under the Stability AI Community License, which allows free use for non-commercial purposes and commercial use for organizations with annual revenue under $1M.
My take: I found it funny they released two versions of the same model where the “Turbo” is the same but just faster. It reminds me of the old Turbo button every PC case had from the mid 1980s to mid 1990s. I am just guessing that everyone using this model, much like the old PC cases, will default to having Turbo mode enabled all the time. Quality-wise both the regular and the turbo version seem to perform almost the same (see chart below).
IBM Launches Granite 3.0 : Open Source Enterprise Models
https://www.ibm.com/new/ibm-granite-3-0-open-state-of-the-art-enterprise-models

The News:
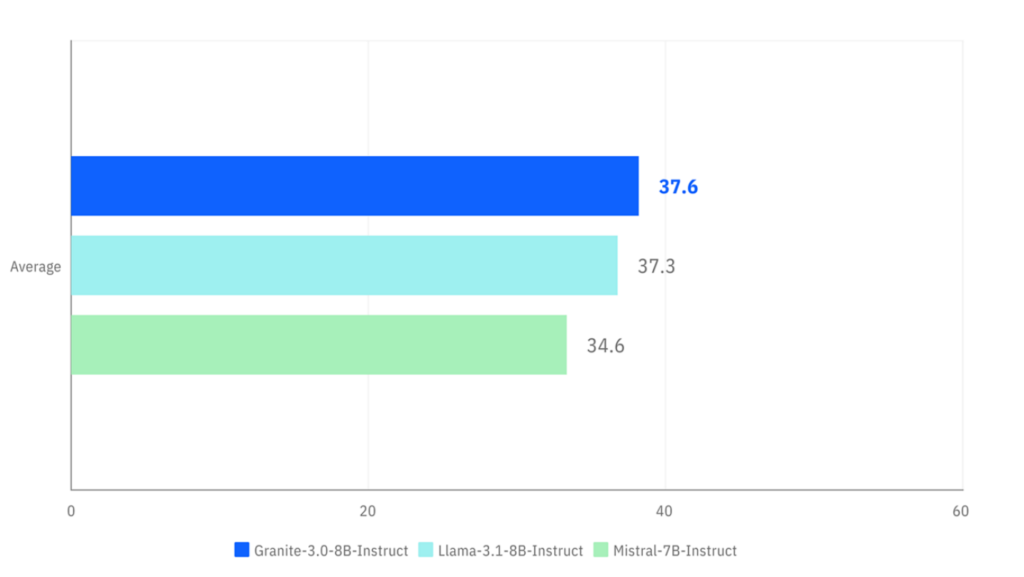
- IBM has released their “Granite 3.0 collection” based on the new model Granite 3.0 8B Instruct.
- Granite 3.0 8B was trained in 12 different natural languages and 116 different programming languages.
- According to IBM, “IBM Granite 3.0 models match—and, in some cases, exceed—the general performance of leading open weight LLMs”.
- IBM Granite 3.0 is released under the Apache 2.0 license and is developed entirely by IBM’s centralized data model factory team.
- IBM Granite 3.0 is specifically optimized for enterprise use cases like RAG, tool calling, and cybersecurity tasks
My take: What exactly is it that makes Granite 3.0 better for enterprise use than other models? According to IBM the “Granite Guardian 3.0” is much better at mitigating AI risks by monitoring user prompts and outputs for bias, violence, profanity, and harmful content, compared to alternatives such as Meta LlamaGuard. Also if you want to use Granite to create, fine-tune or improve another AI model you can name your new model whatever you want. In comparison if you use Llama 3 to fine-tune another AI model, it must be prefixed with “Llama” and you must display “Built with Meta Llama 3” since Meta does not use Apache 2.0 licensing.
Read more:
- IBM doubles down on open source AI with new Granite 3.0 models | ZDNET
- IBM debuts open source Granite 3.0 LLMs for enterprise AI | VentureBeat
- IBM Releases Granite 3.0, Generative AI Purpose-Built for the Modern Enterprise
Meta Launches Mobile-Optimized Versions of Llama 3.2
https://ai.meta.com/blog/meta-llama-quantized-lightweight-models

The News:
- Meta just launched their first “lightweight quantized Llama models that are small and performant enough to run on many popular mobile devices”.’
- The quantized models achieve 2-4x speedup and a 56% reduction in model size compared to the original 1B and 3B Llama models.
- Meta has release numerous examples online such as iOSCalendarAssistant that “takes a meeting transcript, summarizes it, extracts action items, and calls tools to book any followup meetings”.
My take: While these models are definitely small enough to run on almost any phone, they lack many of the optimizations done by Apple on a systems level with Apple Intelligence, such as dynamic loading and unloading of adapters and temporary caching in memory with swapping capabilities. Apple definitely has an advantage over the average Android-developer resorting to Llama here, and I think it will show in the benchmarks next year.
Read more:
New Open Source Video AI Launched : Genmo Mochi 1

The News:
- Genmo is a startup company developing open-source state-of-the-art video generation AI models.
- Their new model Genmo Mochi 1 was released last week as Apache 2.0 open source, which mean you can fine-tune it and use it for whatever you want.
- You can download Mochi 1 from Github.
- You can try Mochi 1 for free on the Genmo Playground.
My take: I know what you are thinking, “I could really use a new AI video generation model”! Right? No? 🙂 Well Genmo Mochi 1 is interesting since (1) it has the highest Elo score of all current models, and (2) it’s open source and uses the Apache 2.0 license. If you have the need for some text-to-video you might as well check it out.
Perplexity Launches Native macOS App
https://apps.apple.com/us/app/perplexity-ask-anything/id6714467650?mt=12
The News:
- In October Perplexity has launched five new features: (1) Finance, (2) Spaces, (3) Internal File Search, (4) Reasoning mode, and now (5) a native macOS app.
- The macOS app includes Pro Search, voice capabilities, thread follow-up and custom global shortcuts.
My take: Great news if you use Perplexity and own a Mac computer! Perplexity is growing like never before, and with the native mac client it will be easier than ever to collect information for your next project.