
- Tech Insights 2025 Week 43

Are we in an AI bubble? In some ways I think we are. Every company that sells an AI-powered service needs to pay for API access to Anthropic, Google or OpenAI to deliver value. This includes companies like Cursor, Lovable, Microsoft, and thousands more. The challenge with this business model is that the regular models like GPT5 and Claude Sonnet 4.5 has become quite costly to run, while not performing that much better than the previous generation. And the best models like Claude Opus 4.1 or GPT5-Pro cost so much to run that it’s not financially viable to use them for any service at all. These top models are typically only available by signing up directly with Anthropic or OpenAI with a personal $200 per month subscription.
I believe this is not the scenario most AI companies planned for six months ago, and today we are being overwhelmed with add-on AI features, agentic solutions and smart assistants promising to solve almost any task. But where are the actual users, and where are the actual returns of the investment? One example of this is the COPILOT function Microsoft introduced in Excel two months ago, where they later had to go out with a warning that users should not use it for numerical calculations and most things people actually use Excel for. The models that are cheap to use are probably not performing as well as most companies expected them to do today.
This is why Microsoft is joining Apple and all the other AI companies in building their own models, so they can own their future and their upcoming AI features. For SaaS companies that do not own their own models, they are quickly becoming part of a big bubble that is just waiting to burst. Because if API prices continue to increase, they will either have to charge their customers more than anyone is willing to pay or significantly lower the output quality of their AI models. And right now most companies are doing the latter. AI slop is one of the more popular terms today, and it’s a good reason for it.
For you as a company you can do two things to stay clear of the AI bubble. First, build your own agentic AI platform that integrates with companies that own their AI models, like Anthropic, Google, OpenAI or Mistral (and soon also Microsoft). This limits the risk of them lowering the quality of their offering due to rising API prices. Secondly, don’t build agentic AI solutions where you’re locked into just one provider. This gives you zero options for price comparisons, and you also cannot benefit from using multiple different models working on the same task. I think one really good example here is the new Veo 3.1 video model from Google. Both Sora 2 and Veo 3.1 are great video models, but they are good at different things. It’s the same with language models, they each have their strengths. This is the real power of agentic AI systems, and this is something you can build and own yourself.
As long as your AI strategy is centered around your own agentic platform using more than one AI model from more than one provider that own their own models, you’re all set for an amazing AI journey far away from any bursting bubbles.
Thank you for being a Tech Insights subscriber!
Listen to Tech Insights on Spotify: Tech Insights 2025 Week 43 on Spotify
THIS WEEK’S NEWS:
- GitHub Open Sources Spec Kit for Improved AI Coding Agent Reliability
- Claude Skills: Modular Task-Specific Packages for AI Agents
- Anthropic Updates Claude Haiku to Version 4.5
- Microsoft Releases MAI-Image-1, First In-House Text-to-Image Model
- Microsoft Brings Copilot Voice, Vision, and Actions to All Windows 11 PCs
- Microsoft Excel Copilot Adds AI Formula Completion
- Google Announces Veo 3.1 with Audio and Advanced Editing
- AI-Generated Articles Plateau After Brief Majority
GitHub Open Sources Spec Kit for Improved AI Coding Agent Reliability

The News:
- GitHub released Spec Kit, an open source toolkit that applies spec-driven development to AI coding agents like GitHub Copilot, Claude Code, and Gemini CLI. The toolkit addresses reliability issues where agents produce code that appears correct but fails to function because developers provide vague prompts rather than clear specifications.
- Spec Kit implements a four-phase workflow with validation checkpoints at each stage. The Specify phase captures high-level requirements focused on user needs and outcomes, the Plan phase defines technical architecture and constraints, the Tasks phase breaks work into discrete implementation units, and the Implement phase executes those tasks.
- Specifications in Spec Kit exist as editable Markdown files in a .specify directory that includes spec.md for requirements, plan.md for architecture, and a tasks/ folder for work units. These files function as version-controlled, living documents that both developers and agents can interpret and refine.
- The toolkit uses a CLI tool called specify to bootstrap projects with template files and helper scripts for different AI agents. After initialization, developers use commands like /speckit.specify, /speckit.plan, and /speckit.tasks to steer agents through the workflow without requiring agent-specific implementations.
- Spec Kit separates stable requirements from flexible implementation details, making it particularly effective for greenfield projects, adding features to existing codebases, and modernizing legacy systems where business logic must be preserved while technical debt is eliminated.
My take: If you have heard me talk about 100% agentic development, you know that my process looks like specification -> implementation plan -> agent code -> code review. GitHub has formalized a variant of this process into Specify -> Plan -> Tasks and Implement, which is more or less the same. I think Spec Kit has its place if you are primarily working with the standard models like GPT5 and Sonnet 4.5, models that typically have problems with detailed planning and working with large code bases. On the other hand if you use OpenAI Codex with the model GPT5-CODEX-HIGH I see much less of a need for it, just make sure to work structurally going from specification to implementation plan, then let the LLM create tasks, subtasks, code and do a code review for you automatically. In the end you and your team need to find a way that works for you, and if you have not even considered a process like this before then Spec Kit is probably a good start.
Read more:
Claude Skills: Modular Task-Specific Packages for AI Agents
https://www.anthropic.com/news/skills
The News:
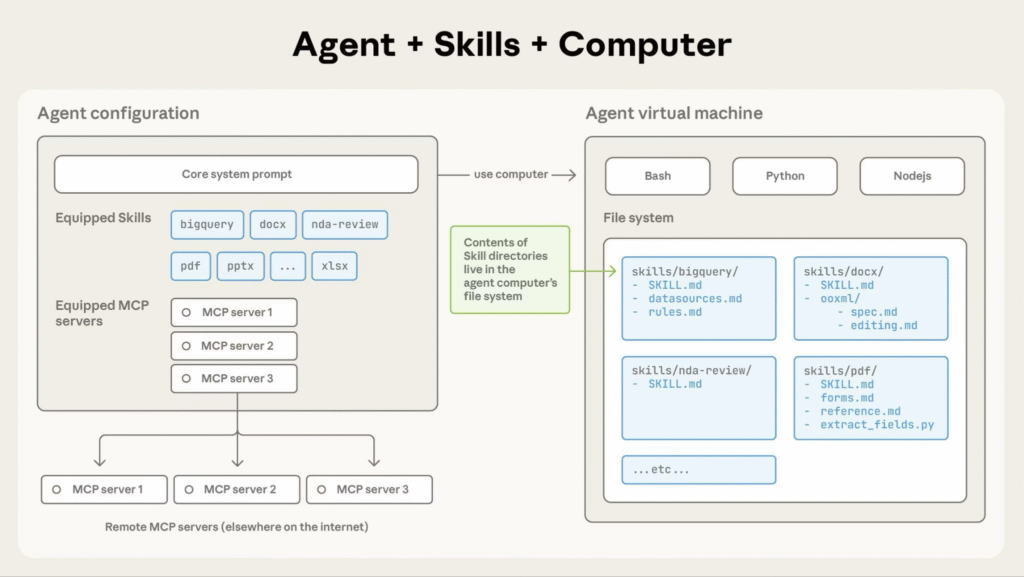
- Last week Anthropic launched Claude Skills, a feature that packages instructions, scripts, and resources into folder-based modules that Claude loads when relevant to specific tasks.
- Skills use progressive disclosure across three levels: metadata (skill name and description, approximately 100 tokens per skill), instructions (under 5,000 tokens when triggered), and bundled resources (unlimited size, accessed via filesystem without loading into context).
- Claude automatically identifies which Skills match the current task and loads only the minimal necessary information, allowing users to install many Skills without context window penalties.
- Skills work across Claude.ai (for Pro, Max, Team, and Enterprise users), Claude Code, the API via the /v1/skills endpoint, and the Claude Agent SDK.
- Anthropic ships 15 pre-built Skills including document creation tools for Word, Excel, PowerPoint, and fillable PDFs.
- Skills can contain executable Python scripts that Claude runs via bash for deterministic operations like sorting lists or extracting PDF form fields, without consuming context tokens.
- Companies including Box, Canva, Notion, and Rakuten have integrated Skills into their workflows, with Box reporting tasks that previously took a day now complete in an hour.
My take: So, what is Claude Skills? Claude Skills is technically a compressed file folder with three things: (1) a markdown file with instructions on how to perform certain tasks, (2) optional scripts like python code, and (3) reference files like templates and style guides. When a skill is added to Claude, Claude will scan the names and short descriptions of all skills in the package if there is a match for the current prompt, and then it will load the full instructions (up to 5,000 tokens) for the current work task. Only after that will it will access reference files or run scripts. The closest comparison to Claude skills are OpenAI CustomGPTs. This is excellent news for companies rolling out Claude in their organization, where users can now share prompts, work processes, scripts and reference files in a standardized way.
Read more:
Anthropic Updates Claude Haiku to Version 4.5
https://www.anthropic.com/news/claude-haiku-4-5
The News:
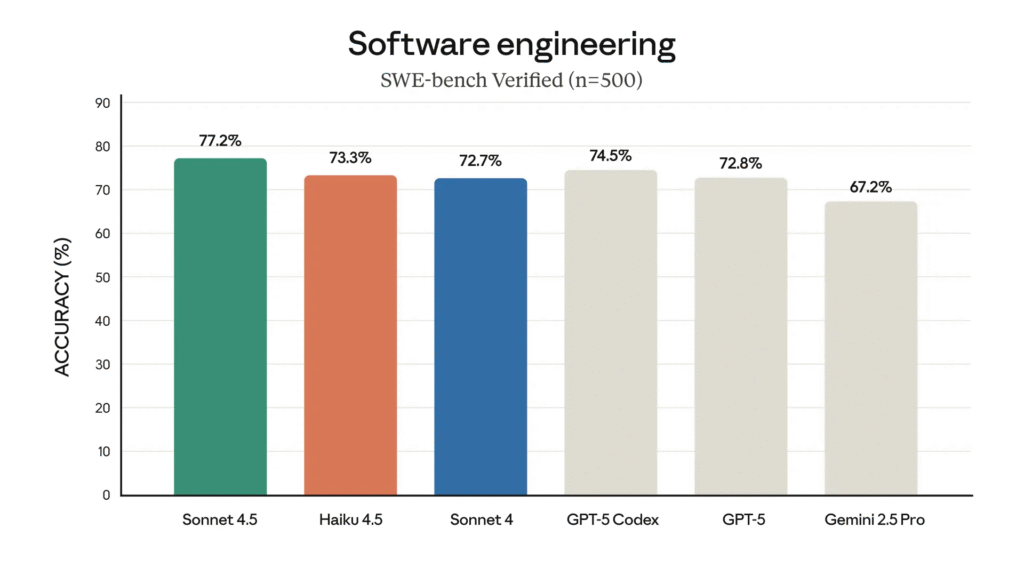
- Anthropic released Claude Haiku 4.5, a small AI model that matches Claude Sonnet 4’s coding performance at one-third the cost ($1 per million input tokens, $5 per million output tokens) and more than twice the speed.
- The model scored 73.3% on SWE-bench Verified and 41% on Terminal-Bench, matching Sonnet 4 and GPT-5 performance on coding tasks.
- Haiku 4.5 surpasses Sonnet 4 in computer use, basic math, and agentic coding tasks.
- The model runs 4-5 times faster than Sonnet 4.5 while delivering 90% of Sonnet 4.5’s performance in agentic coding evaluations.
- Available through Claude API, Amazon Bedrock, and Google Cloud Vertex AI, with deployment as a drop-in replacement for both Haiku 3.5 and Sonnet 4.
- The model supports vision, 200,000 token context window, and extended thinking mode.
- Anthropic classified Haiku 4.5 under AI Safety Level 2 due to lower incidence of misaligned behaviors compared to earlier versions.
My take: When it comes to benchmarks, I still post them but I don’t trust them. My experience with scores on SWE-bench says very little how the model will perform when context is pushed to the limit with large code bases, even if it can do some isolated tasks fairly well. Tests so far has not backed up Anthropic’s claims either, for example codelens wrote: “Claude Haiku 4.5 Wrote 62% More Code But Scored 16% Lower Than Sonnet 4.5”. That’s basically my experience as well. The smaller models score pretty high on benchmarks since they spam write code, but you need to upgrade to a model like GPT5-CODEX to get models that write code that’s well-thought out and is maintainable. There are lots of uses for Haiku, but programming is not what I would use it for, despite being one of the key areas Anthropic mention in the release. My advice to all companies wanting to get up to speed with agentic development is to not waste your time on these smaller models, go straight for the top models that are only available in Claude Code or Codex CLI.
Microsoft Releases MAI-Image-1, First In-House Text-to-Image Model
https://microsoft.ai/news/introducing-mai-image-1-debuting-in-the-top-10-on-lmarena
The News:
- Microsoft released MAI-Image-1, its first text-to-image generation model developed entirely in-house, which debuted at ninth place on the LMArena text-to-image leaderboard with an ELO score of 1096.
- The model generates photorealistic imagery with focus on complex lighting effects such as bounce light and reflections, landscapes, and textures.
- Microsoft trained the model using data selection and evaluation processes informed by feedback from creative industry professionals to reduce repetitive or generically stylized outputs.
- Microsoft emphasizes faster generation speeds compared to many larger competing models, supporting rapid iteration and handoff to other creative tools.
- MAI-Image-1 is currently available for public testing on LMArena and will be integrated into Copilot and Bing Image Creator soon, which currently rely on OpenAI’s GPT-4o and DALL-E 3.
- This release follows Microsoft’s August 2025 launch of two other in-house models, MAI-Voice-1 and MAI-1-preview, as part of its strategy to reduce dependence on external AI partners.
My take: The only way Microsoft will stay relevant with their Copilot offering in the future is to own their own models, and I expect Microsoft to release lots of new models in 2026. With MAI-Image-1 Microsoft now has three strong models for text, voice and imaging and while they are behind the competition today in terms of performance, it’s a solid foundation for them to build upon for years to come. I would not be surprised to see M365 Copilot to move over to MAI-2 in 2026 as the default LLM for Copilot, and then provide access to Claude and ChatGPT as backup options with limited availability.
Microsoft Brings Copilot Voice, Vision, and Actions to All Windows 11 PCs
https://blogs.windows.com/windowsexperience/2025/10/16/making-every-windows-11-pc-an-ai-pc

The News:
- Microsoft makes Copilot Voice, Vision, and Actions available on all Windows 11 devices, positioning every PC as an AI-capable machine regardless of hardware specifications.
- Copilot Voice now supports “Hey Copilot” wake word activation, enabled as an opt-in feature through the Copilot app settings. The wake word spotter uses a local 10-second audio buffer stored on-device and never recorded, though internet access is required to process user requests. Microsoft reports users engage with Copilot twice as much when using voice compared to text input.
- Copilot Vision expands worldwide with full desktop and app sharing, allowing the AI to analyze content on screen and provide guidance. Vision can now access complete context in Word, Excel, and PowerPoint files beyond what appears on screen. A text-based Vision mode will roll out to Windows Insiders, allowing users to interact via text instead of voice.
- Copilot Actions enters preview in Windows Insider Program and Copilot Labs, enabling AI agents to perform tasks on local files like sorting photos or extracting PDF information. Actions runs in an isolated environment with its own desktop, and users can monitor progress, take control, or disable it at any time. The feature is turned off by default and requires explicit user permission.
- Microsoft integrates Manus, a general AI agent from a Singapore startup, into Windows 11 through File Explorer and as a standalone app. Users can right-click documents and select “create website with Manus” to build websites in minutes without uploading or coding. Manus leverages Model Context Protocol to access local files.
- Copilot connectors allow linking OneDrive, Outlook, Gmail, Google Drive, Google Calendar, and Google Contacts to Copilot on Windows. Users can search across connected services using natural language queries like “Find my dentist appointment details” or “What is the email address of Mary”.
“With the new Manus AI action in File Explorer, you can get help with complex tasks like creating a website using the documents in your local folder with just one click.”
My take: Wow this was unexpected. Microsoft is integrating the Singapore startup AI agent Manus straight into Windows 11, so when you right-click a document you will now be shown the option to “create website with Manus”. Manus uses the new MCP connectors built into Windows 11 to retrieve documents and create websites. Microsoft is really going all-in on AI, experimenting and testing, adding AI to every single corner of every software they own. Where Apple is going slowly, developing their own models that can run locally on devices, Microsoft is integrating both Claude, OpenAI and third party services like Manus straight into the Windows 11 experience. What is your opinion of this? Do you use Windows, and is this the way you want Windows to evolve?
Microsoft Excel Copilot Adds AI Formula Completion
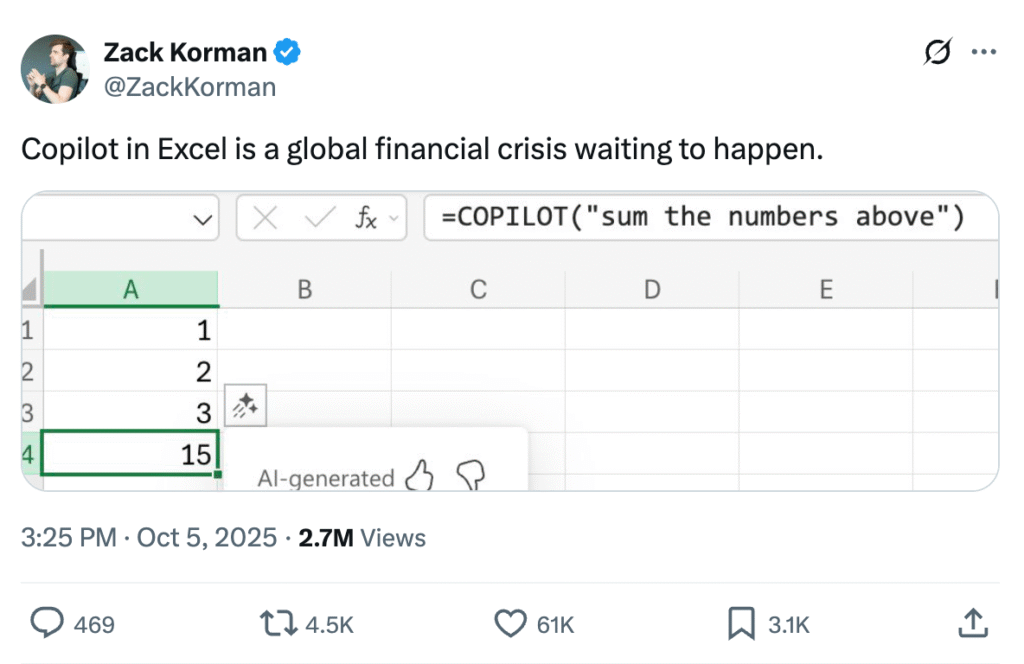
The News:
- Microsoft released formula completion in Excel Copilot, a feature that suggests complete formulas when users type “=” in a cell. The system analyzes worksheet context including headers, nearby cells, formulas, and tables to generate suggestions with result previews and natural language descriptions.
- Formula completion updates suggestions in real time as users type additional characters. If typing “=M…”, the system refines its recommendations until finding an appropriate match.
- The feature handles calculations across varying complexity levels, from basic year-over-year percentage changes to dynamic array formulas and REGEX patterns for data extraction like ZIP codes. It can reference data from different ranges or tables within the same worksheet.
- Formula completion works best with clear column headers and descriptive labels in adjacent cells. Microsoft notes the feature currently does not support formulas referencing other worksheets, with potential support in future updates.
- The feature rolled out September 2025 for Excel for the web in US English only and Windows Insider Beta. Users can opt out through File > Options > Copilot by checking “Hide formula completion suggestions” and selecting a timeframe.
My take: Two months ago Microsoft rolled out the COPILOT function in Excel, calling it “a major step forward in how you work with data”. What I thought was interesting about that release was everything you should NOT use this new function for according to the official documentation:
When NOT to use the COPILOT function (according to official documentation)
To ensure reliability and to use it responsibly, avoid using COPILOT for:- Numerical calculations
- Responses that require context other than the ranges provided
- Lookups based on data in your workbook
- Tasks with legal, regulatory or compliance implications
- Recent or real-time data
So. If you do not care about reliability or accurate data, please feel free to give the COPILOT in Excel a go. 😬 It’s still not clear if it’s the same logic that is powering this new formula completion that was launched last week, but it might be.
Looking at everything Microsoft does when it comes to AI, like semi-integrating Claude into Copilot while still letting it run in AWS servers, adding Manus directly to Windows 11, and the new COPILOT function in Excel where Microsoft says you should not use it for numerical calculations, I cannot help but feel that they are building a quite rocky foundation for 2026. Add to that their own three custom LLMs that will probably soon take over as the default models, and it looks like it could be quite the mess going forward.
Read more:
Google Announces Veo 3.1 with Audio and Advanced Editing
https://blog.google/technology/ai/veo-updates-flow

The News:
- Veo 3.1 is Google’s updated video generation model with synchronized audio, including dialogue, ambient sound, and sound effects.
- Audio generation now extends to existing Flow features such as “Ingredients to Video”, “Frames to Video”, and “Extend”, which can create videos lasting over one minute by continuing from the final second of a previous clip.
- The model generates videos at 720p or 1080p resolution in 4, 6, or 8-second base durations, with support for 16:9 and 9:16 aspect ratios.
- Flow’s new “Insert” tool adds objects or characters with automatic handling of shadows and scene lighting, while an upcoming “Remove” feature will eliminate unwanted elements.
- Users can provide up to three reference images to maintain character consistency across multiple shots or apply specific visual styles.
- Veo 3.1 and Veo 3.1 Fast are available through the Gemini API, Vertex AI, and the Gemini app, with over 275 million videos generated in Flow since its launch five months ago.
My take: It’s interesting how both Veo and Sora evolve in parallel, and seem to release new versions around the same time too. Both Sora 2 and Veo 3.1 are amazing video generators, but each model has its own unique strengths and weaknesses, very much like all the large language models we use (Copilot, ChatGPT, Claude, Gemini). If you want to produce content with AI today you probably want to use both Sora and Veo. Response from user forums have been very positive, where Veo 3.1 seems to excel at textures and lightning, and Sora 2 excels at frame-by-frame precision and stylization.
AI-Generated Articles Plateau After Brief Majority
https://graphite.io/five-percent/more-articles-are-now-created-by-ai-than-humans
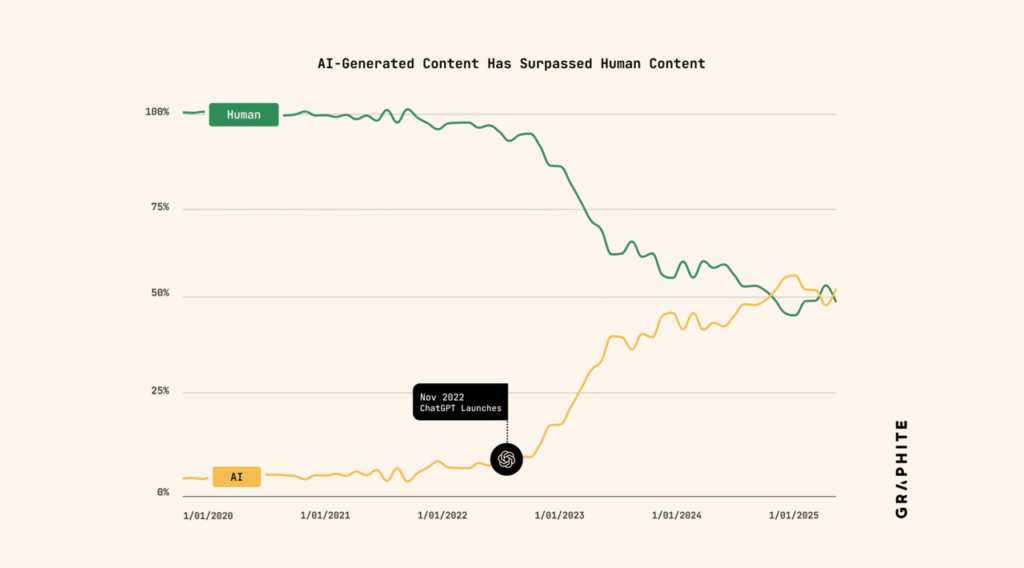
The News:
- Graphite analyzed 65,000 articles from Common Crawl published between 2020 and 2025, using Surfer’s AI detector to classify authorship.
- AI-generated articles briefly surpassed human-written content in November 2024, but growth has since plateaued at roughly equal levels.
- AI article production surged after ChatGPT’s launch in November 2022, reaching 39% of all published articles within 12 months.
- Google Search shows only 14% of ranked articles are AI-generated, while 86% remain human-written.
- ChatGPT cited human-written articles 82% of the time in its responses.
- Surfer’s detector showed a 4.2% false positive rate (human articles classified as AI) and 0.6% false negative rate (AI articles classified as human).
My take: In 2024, Europol warned that 90% of all content available online could be synthetically generated by AI, based on the growth figures available at that time. And if you look at the graph above, it’s easy to see that since the growth of AI generated content increased almost linearly, until it stopped growing in early 2024. The report by Graphite suggests AI content farms realized their output performed poorly, so that producers either became much better in deceiving AI language identifiers, or they just switched back to manual writing. I think it’s the former, I think AI content producers just have become much better at producing texts that do not flag as AI generated.
Read more: